台灣產業AI化的問題6〉打造第一支人工智慧團隊?這麼開始!
企業發展 AI,為什麼需要建立自己的團隊?為什麼資料科學家會被《哈佛商業評論》稱為 21 世紀最有吸引力的工作?企業要如何讓 AI 團隊發揮最大能量,加速公司的成長?
與其在人力市場上痴痴等待高手出現,最有效的策略是,挑選內部員工來做教育訓練,適時地搭配來自外部的輔助,讓他們成為「雙軌人才」,在原本的專長領域之外,外加人工智慧,由他們來組成企業專屬的人工智慧團隊。
在前幾堂課,我們談到導入人工智慧前企業應有的準備,包括要有正確的認知,要有資料基礎建設,確認導入的問題標的及 KPI,接下來的關鍵步驟就在,誰來進行人工智慧的初步導入;換句話說,企業中的第一個人工智慧團隊該如何組成。
通常人工智慧團隊的核心成員有資料科學家、資料工程師及機器學習工程師三種專家。我們可以各用一句話來描述他們的特長,資料科學家擅長連結資料與商業價值,資料工程師擅長蒐集及處理資料,機器學習工程師擅長演算法,從資料裡頭榨取出最多的資訊,讓人工智慧系統的決策更精準。當然也有人可以身兼多種職務,團隊成員可多可少,初期若有資源疑慮,也可以先從兩、三個成員開始,先求有,再求好。
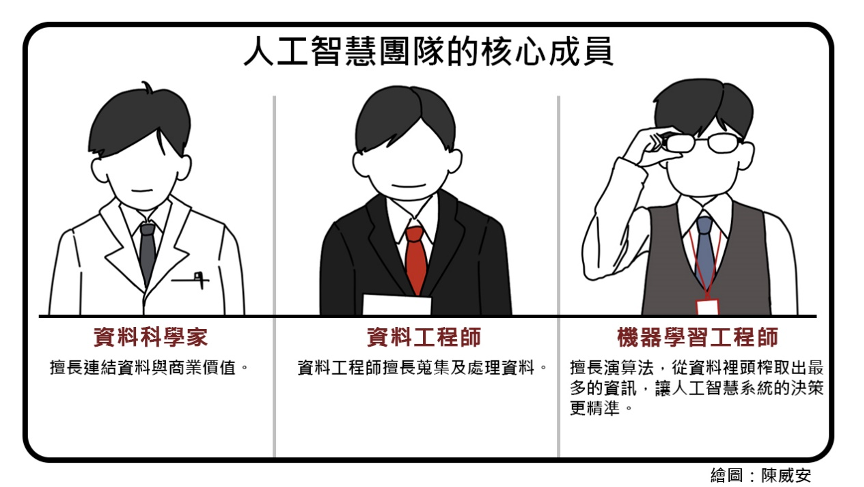
在這三種職位中,又以資料科學家這種職稱最廣為人知,因此我最常被問到的問題是,什麼是資料科學家?資料科學家必須具備哪些能力?是不是資訊背景出身的人,才能擔任資料科學家?
資料科學家應該具備的能力
以定義而言,資料科學家就是能夠處理、分析資料,讓資料能夠為企業產生商業價值的專業工作者。在技術面上,資料科學家必須在資訊、統計、企業業務範圍等三種領域都有一定的造詣,他們不一定非要資訊背景出身,無論是資工、電機等工程背景,數學、統計、經濟等數理背景,或其他與產業專業相關的科系。只要對該產業有一定的商業知識及嗅覺,並有一定的程式及資料分析能力,都有機會成為炙手可熱的資料科學家。
要強調的是,資料科學家的專業能力中,程式及資料分析能力當然有其門檻,但更難得的是商業敏感度,可以嗅得出商業上的潛在威脅、挑戰與機會。商業敏感度不會憑空出現,想成為一位稱職的資料科學家,不只要在資料科學精益求精,更需要常和業務前線的人在一起,不只是一起開會,最好還要一起喝茶、吃飯,藉此了解企業與客戶的互動,還有客戶的需求及痛點,回頭面對數據時,更能找出隱藏在其中的商機。
這也能解釋為什麼,我們對資料科學家的人格特質也有一定的期待,除了細心與溝通能力之外,最好還有一定的創意。細心是因為資料科學家是解讀資料的人,解讀錯誤將會造成災難;溝通能力是因為資料科學家有大半的時間都在與蒐集資料的人、保管資料的人、能夠解讀資料的人、做業務決策的人以及將被流程改善影響的人做溝通,擅長溝通才能夠事半功倍。
那為什麼資料科學家需要創意?因為有創意的人才懂得在企業流程常規中,提出一般人所不疑的疑點。資料分析不是魔術,無法直接告訴我們問題所在,必須要有人先透過觀察找出潛在的問題,才能以資料來證明問題所在,再來用機器學習改善問題。第一個步驟總是由人來提出問題,因此,最高明的資料科學家必須能在「不疑處有疑」,不會把常規的企業或商業流程視為理所當然,而能夠在理所當然之中提出大膽假設,並以資料分析小心求證。
企業內部建立 AI 團隊的必要
談到這裡,可能有些聽眾開始懷疑:想喝牛奶真的需要養一頭牛嗎?難道我們不能夠直接導入既有的套裝軟體或者聘請顧問公司就好?在上一堂課,我們已經談過,以今天的人工智慧技術來說,並沒有即插即用的套裝軟體,通常需要大量的客製化工作。即使自行開發,系統及流程整合的工作往往也無法避免,因此我們這裡所談的人工智慧團隊並不見得一定要做系統開發,而是熟悉企業業務、流程、資料、及目標,能夠確認切入點的合理性及資料可用性,能夠與內外部團隊協同合作,並擔任產品及績效管理的專業團隊。
就產業 AI 化來說,我們不見得需要最先進的人工智慧技術,經常可以就既有的技術來解決企業本身的問題。因為要解決的問題、領域知識以及資料,都在自己家裡,因此,若能培養自己的人工智慧團隊,不論接下來系統要自建或是外包、外購,才能有足夠的掌握度來確認目標及進程,並且做實質的績效管理。
下一步,就是很多企業頭痛的問題了,這些專業的資料科學家、資料工程師及機器學習工程師該去哪裡尋找?
善用人工智慧民主化趨勢
坦白說,因為機器學習技術進展神速,只要從學校畢業超過兩年,不可能在學校中學過最先進的機器學習及深度學習技術,因此很難在市場上找到厲害且富經驗的人工智慧人才,就算要挖角也無從挖起。這個現象不只是在台灣,全球各大企業都同樣在想盡辦法尋求有經驗的人工智慧高手加入。
幸運的是,這一波,也是人類歷史上第三波的人工智慧浪潮,伴隨著一個我們稱為「人工智慧民主化」的趨勢,其中最重要的概念是,人工智慧技術不應該只被某些跨國企業所壟斷,應該讓所有需要的人都有機會參與及使用。具體的作法包含各種機器學習開發工具及模型的開放源碼,以及各式最新核心技術的分享等等。
因此,我的建議是,趁著這一波人工智慧民主化的趨勢,與其在人力市場上痴痴等待高手出現,最有效的策略是,挑選內部員工來做教育訓練,適時地搭配來自外部的輔助,讓他們成為「雙軌人才」,在原本的專長領域之外,外加人工智慧,由他們來組成企業專屬的人工智慧團隊。台灣人工智慧學校以及為數不少的線上教學平台,都提供人工智慧的訓練課程,但要記得這一波的人工智慧技術以工程為主,理論為輔;因此,在教育訓練一定要包含大量的實作課程,才能夠訓練出有實戰能力的部隊。
讓AI團隊完全展現能量的 3 大關鍵
當人工智慧團隊建立起來後,企業仍然有許多資源、組織面及文化面的支持工作要進行,才能讓團隊全力展現能量。最基本的第一步是,要有足夠的軟硬體來支持機器學習程式的運行。全球的人工智慧發展目前走到軍備競賽的地步,若是同一個題目,同業花一小時可以訓練出一個機器學習模型,但內部團隊因為計算設備不足必須花十小時才能做到同一件事,那麼,同樣的時間內,同業可以嘗試十種不同的參數組合,我們只能嘗試一種。除非天縱英明,不然在大多數情況下,我們的演算法表現就是會比別人差一截。
第二點,要讓他們能夠取得所有該取得的資料。這聽起來很荒謬,但我認識不少人工智慧團隊的工作瓶頸,是無法取得自己公司裡頭的資料,可能原因很多,包含企業尚未認清資料是企業資產,而非各部門擁兵自重的資產,因此形成我們所謂的「資料孤島」或「資料穀倉」。要解決這類型的問題唯有企業主將企業資料治理視為重點策略,並且投注長期的支持。
第三點,建立容許實驗的文化。我們都知道高報酬的投資必然有風險,但是十分弔詭的是,在很多企業中,專案只許成功,不許失敗,人工智慧這樣尚未成熟的技術在不許犯錯的企業文化中要好好發展尤其困難。
對人工智慧技術發展熟悉的聽眾應該都知道 Google Brain 這個團隊,在此團隊中,工程師被鼓勵進行高報酬、高風險的研究,他們的KPI不與失敗綁定,只與最終效益有關。即使某位成員的實驗老是失敗,最糟狀況就是無法加薪。但對於高階的管理者來說,若不進行高報酬也伴隨高風險的計畫並取得成功,是很難再繼續晉升的。對於資料分析及人工智慧團隊來說,他們需要一個容許嘗試錯誤、以最終產出為依歸的環境,才能嘗試不同的可能,針對不同的問題找到有效的解法。

說到這裡,我們來總結今天的課程,發展人工智慧的要素有四:人才、資料,演算法及運算能力。人才與資料是重中之重,往往是決勝的關鍵。演算法因為人工智慧民主化的趨勢,全球的水平雖然有差異,但若以產業AI化,尤其是企業內部運用而言,差異不會太大;而運算能力是純粹的硬體投資,取得相對最容易。
因此,已經打造流程自動化及資料基礎建設的企業,應該要把握這個機會及時間點,儘早在公司內部打造人工智慧團隊,開始探索人工智慧的可用之處。團隊再小也沒關係,重點是儘早將問題定義清楚,建立好資料蒐集機制,納入企業日常運作中,以開放源碼工具儘早驗證資料的可用性,以及人工智慧可能帶來的價值,才能將自己準備好,日後不論是建立正規部隊或是導入外部系統,都能讓人工智慧為企業產生最大價值。
下一堂課,會開始與大家分享不同產業如何應用人工智慧來改善企業流程及提升競爭力,第一個案例是擔負台灣經濟命脈的製造業。
- 主辦暨執行單位:
財團法人台灣人工智慧學校基金會 - 協辦單位:
中央研究院資訊科學研究所、中央研究院資訊科技創新研究中心 - 捐助企業:
台塑企業、奇美實業、英業達集團、義隆電子、聯發科技、友達光電、新光人壽-新壽管理維護
Copyright© 台灣人工智慧學校 | Taiwan AI Academy 版權所有