Finance AI 人工智慧在金融保險業中的應用 - 林愛哲 Tom Lin
引言
在本篇文章中,將整理過往我在台灣人工智慧學校中所帶過的金融與保險專題與個人研究,略略分享作為金融從業人員,如果妥善掌握AI,優化自身業務,與在AI導入過程中,如何克服常見的困難。分享實例包含:
- 如何掌握機器學習模型,處理連續性數值的預測。
- 如何應用自然語言處理模型,從法律文件中,粹取出有用的資訊。
Technique General Overview
在人工智慧領域中,我們可依照應用的「資料結構」與「技術」約略區分為三大分支:
- 結構型資料:依統計理論為背景建置的模型,或是強調在擬合資料分佈狀況的機器學習(ML)。
- 圖片型資料:不論是圖片、影片,都可使用深度學習中的電腦視覺(CV)模型,進行圖片資訊的粹取與預測。
- 文字或時序型資料:最後在人類語言訊息的粹取,或是與時間序列資料有關的資料,都可以使用自然語言處理(NLP)的模型進行預測。
因此,落地到金融業中,我們可以如何妥善應用人工智慧,優化金融業者的既有業務,並且深化其在同業中的競爭優勢呢?
下表是倫敦Fintech研究機構Autonomous Research在2019年,針對銀行業,以前中後台三個階段,分析AI所能夠帶來的價值提升。
從圖中,我們可看到Conversational Banking,這就是應用了NLP的技術;而Anti-fraud and Risk的模型,常常是建置在ML技術上;最後我們看到的AI Bio-metrics Technology,就會是使用CV的模型處理。
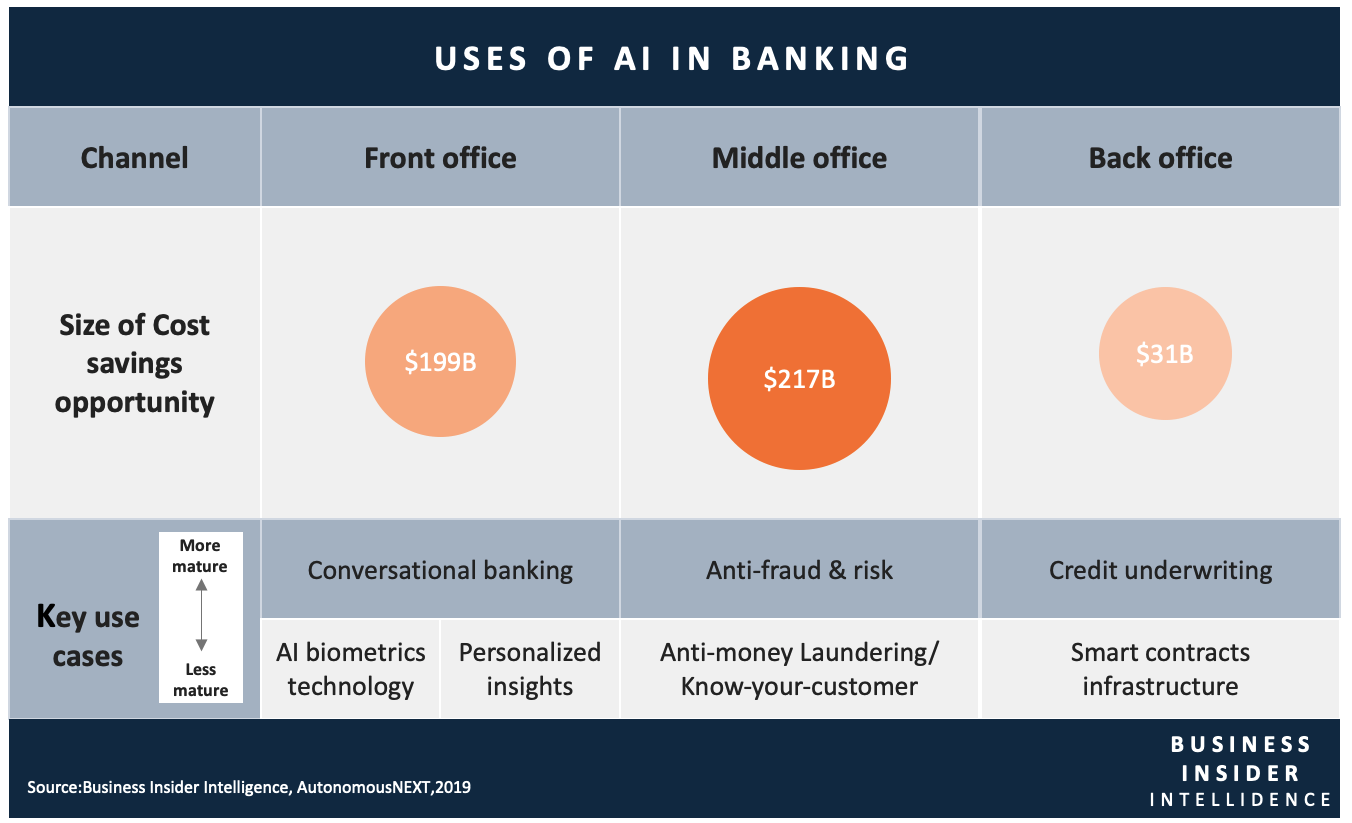 資料來源:https://www.businessinsider.com/ai-in-banking-report
資料來源:https://www.businessinsider.com/ai-in-banking-report因此,回到本篇的主旨,就讓我們事不宜遲,來看看有哪些具體AI應用在金融服務,特別是保險業當中,並且我們又該如何克服模型建立中所會遇到的問題吧!
案例分享一:保費預測
背景說明
對於一份保險來說,保險業者與客戶雙方應該最重視的是保險費用。在某些特殊的保險,保費的估計會因為種種外在的條件而有很大的差異,保險公司因而需要花人力與時間來報價。是否有更好的方法來輔助保險公司,是我們這個案例想分享的重點。
專案目標
— 透過Machine Learning的技巧,學習過往保費估價人員進行估價的hidden Know-how,透過此方式,自動化後續保險案件的估價流程。
在處理此問題時,我們可以羅列出模型建置中,最常出現的幾大問題,這些問題不限於專案,其實在許多其它使用結構化資料進行建模時,也會常常碰到的困難。
- 難題一:缺失值的處理
- 難題二:離群值/偏態的處理
- 難題三:類別欄位的值特別多 (High Cardinality)
- 難題四:如何進行特徵解釋
接下來讓我們一一來探討,面對這些問題,可以如何處理。
缺失值的處理
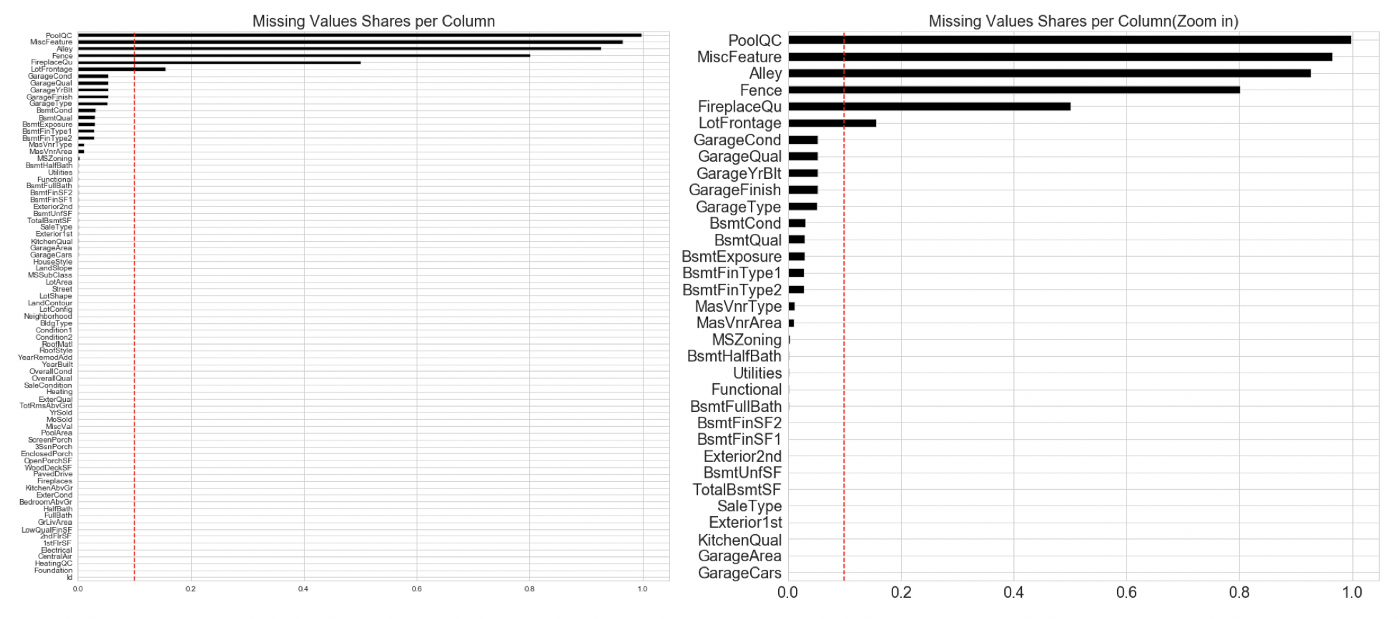 為保護資料源,在此使用公開之Boston House Price資料集,作為示範
為保護資料源,在此使用公開之Boston House Price資料集,作為示範在處理缺失值上,我們可以先使用horizontal bar chart來進行觀察,也可以繪製輔助線,如上圖中的紅色直線,作為是否要將該欄位刪除的依據。
更完整的EDA,其實也可以使用一些既成開源的套件,例如 missingno 或是 pandas-profiling,這些都可以幫助我們更了解資料。重要的是,透過視覺化的方式,來察看missing value是否有一個固定的pattern,這樣方便我們判別是否資料在收集來源處,就出了問題,需要深入了解。
一般在面對數值欄位的缺失補值,都會以平均數,或是中位數替代,比較sophisticated的作法,則會使用 SMOTE,相關的介紹,可以查看所附連結。
面對類別值欄位,我們最直觀的作法是使用眾數進行補值,但是這有個盲點,我們需要看類別值的出現頻率,是否是近似uniform distribution,還是主要集中在幾個類別值上。眾數補值的作法,通常僅適用在有高頻的類別值上,才比較適合,否則將缺失值歸類到其它,或是直接discard整筆資料,也是一個作法。
離群值/偏態的處理
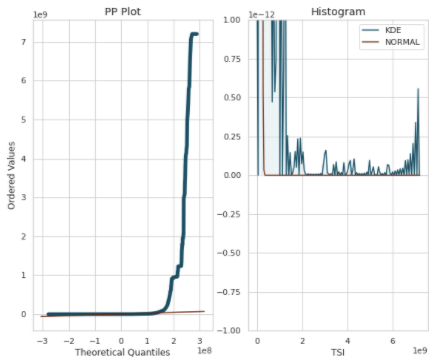 針對目標變數的分佈,繪製PP Plot與Density Histogram
針對目標變數的分佈,繪製PP Plot與Density Histogram針對離群值/偏態,可以直接先觀察目標變數的分佈情況,如果其呈現高度的偏態,如上圖所示,或許我們可以猜測這個群體,其實是由多個分佈組合而成,比較好的作法,特別是在有雙峰的情況下,是直接將資料集依照目標變數的分佈,進行切割,再各自建模。
類別欄位的值特別多(High Cardinality)
High Cardinality — 指的是類別欄位中,類別的種類太多了,最極端的狀況,就是User ID,當將這類的欄位,使用一般的One-Hot-Encode,放入Feature Set當中進行建模,模型往往不容易進行收斂,並且運算量會變得非常大,因此比較適當的作法,一是可以使用簡易的Label-Encode,之後再使用Tree-based的非線性模型,進行擬合。比較advanced的作法,可以使用embedding的方式(當然前提是資料筆數夠多),將類別值,壓縮到一個小維度的space上頭,使用該方式也能夠讓對target variable的impact相似的類別值,會有比較相同的vector。
另外一個模式,是透過特徵篩選後,只選定幾個比較重要的類別欄位,與該問題的domain expert一同討論,一個個欄位,來重新分類裡面的類別值,截取出最重要的幾個類別值,而將不重要的值,統一歸納到其它值,透過這樣對資料仔細的調整,最後建置出來的模型,一般來說準確度會非常高。
如何進行特徵解釋
導入AI模型中,往往我們不單只希望產出一個可進行預測的模型,我們也會希望能夠透過模型,告訴我們哪一些最重要的因子,如何來影響我們在意的target variable,例如此例的保費。
過去我們可以透過觀察迴歸模型的係數,來了解特徵對於目標變數的影響,但是隨著我們可以使用的模型越來越複雜,像非線性的tree-based model甚至是DNN模型,如何從這些模型中,取得特徵對於target variable的影響,就很重要。
在這邊我們使用了兩種方法,一種是常見的feature importance,另外一個則是SHAP value。
![[資料來源] Feature Importance的效果呈現示意圖](/wp-content/uploads/2021/05/figb3.png) [資料來源] Feature Importance的效果呈現示意圖
[資料來源] Feature Importance的效果呈現示意圖![[資料來源] SHAP values典型的成效圖](/wp-content/uploads/2021/05/figb4.png) [資料來源] SHAP values典型的成效圖
[資料來源] SHAP values典型的成效圖Feature Importance這個在tree-based model下很好的工具,有一個致命的缺陷,那就是我們僅得知這個特徵很重要,但無法得知它對target variable是正向或是負向的影響。因此SHAP values就因應這個需求而誕生。
使用SHAP values,我們不但可以知道哪些特徵是最重要的,同時它對於target variable是正向或是負向的影響,都可以透過視覺化的方式呈現。如同上方的示意圖,紅色值代表特徵值越大,如果它對應的SHAP value越大,就表示它對target variable的正相關越明顯。
如果對於SHAP value的計算原理,想更進一步地了解,可以閱讀本校Evans助教曾寫過的兩篇深入淺出的SHAP介紹,與另外一篇發表在towards data science上的文章:
- Explain Your Machine Learning Model by SHAP. (Part 1)
- Explain Your Machine Learning Model by SHAP. (Part 2)
- Explain Your Model with the SHAP Values
最後成果
透過上述一系列的作法,在處理保費自動報價上,模型可以達到R²分數0.9以上的準確度,並且在使用連續三個季度的資料,進行驗證,其R²分數,都非常穩定,表示模型的表現非常robust。
許多人對於建模,往往會認為使用複雜的Ensemble modeling,才可以建構出最佳的模型,但是使用Ensemble,一方面會消耗大量的運算資源,並且容易有over-fitting的狀況,在本案中,可以佐證透過適合的資料前處理,使用一般的模型(簡易的Random Forest Model),就能夠on par with ensemble model的精準度。
本案例仍然以結構型資料並素材,進行模型建置,但目前在國外,已開始有保險理賠業者利用非結構化的影像,進行模型訓練,從而透過模型的自動判斷,簡化理賠流程。詳細內容,可參考此此連結:“AI 計算汽車理賠,汽車維修業大敵來了”
案例分享二:金融法律文件的重要元素粹取
背景說明
在保險業務中,保費估算是一個重點,另一個重點是保險合約。對於保險公司而言,合約的條款一旦有錯誤,會影響成千上萬的保戶,並且造成保險公司巨大的損失。因此保險公司需要花大量的人力進行保單文件的校對,是否有更好的方法來輔助保險公司,是我們這個案例想分享的重點。
專案目標
— 透過NLP當中的BERT模型,依特定情境需要而客製訓練Named Entity Recognition模型。透過該模型,highlight出最法律文件當中最需要再次校訂的部份,方便文件審核人員偵錯與對照。
處理NLP問題時,有兩大方式,可以處理,一是較為傳統的rule-based text parsing,像是正則表達法(regular expression);另一個則是新近常見的Deep Learning(DL) transformer model,以下是我們在處理NLP問題時,常需要預先思考的面向。
- 難題一:Rule-based V.S. Model-based
- 難題二:如何定義好的元素類別
- 難題三:訓練資料的處理技巧
- 難題四:如何提升少數樣本的類別準確度
接下來,我會一一藉著對這些問題的探討,來分享如何建構一個高品質的NLP模型。
Rule-based V.S. Model-based
針對NLP的問題,許多人一開始會跳下去直接使用最複雜,當然也是最先進的DL模型。但其實有許多問題,或許直接透過rule-based的regular expression,就可以達到非常好的成效。依照sapCy套件作者的意見,如果我們手頭上要parsing的text,使用regular expression就可以達到九成以上的準確度,那麼或許我們就不一定要直接跳到使用DL NLP model。
那麼,何時我們需要轉向使用model-based的NER模型呢?
最直觀的判斷,就是使用regular expression的方式,有沒有辨法有效identify出我們想關注的字詞。例如,如果字詞在文本context中會有多義的狀況出現,那麼這個字詞可能就會被mis-labeled。
另外一個狀況是想關注的詞彙類別,會有變型出現,那使用rule-based的方法,就會漏標註這些資料,例如,針對存款產品,會出現:活期存款、定期存款、證券存款、甚至是現在衍申的員工存款、綠存款等。
如果是為了要因應辨別未來變型的詞彙,使用model-based的方式,往往會比rule-based的方式來得好,因為model-based的方式,是透過辨識詞彙在句子中的相對關係,來判斷詞彙的類別,這讓模型更為flexible,可以處理新衍生的詞彙。
如何定義好的元素類別
在建立一個NER模型時,最常出現不知道該如何將想關注的詞彙,分成幾大類的狀況。這通常是需要一個不斷修正的過程,建議的方式,是先將類別區隔的比較細,這樣即便後來想要使用比較大類的類別進行訓練時,也不需要重新label資料,將其中幾項類別合併成「中類」或是「大類」即可。
另一個在設定label類別過程中,需要確認是否這個類別定義是非常清楚,也就是self-explanatory,實務上,可以讓兩位以上的資料標注人員label同一份文件,如果大家對於要將哪些詞彙歸納在哪個類別上,都沒有什麼歧異,那就表示這個label的類別定義應該是清楚好判斷的。
這個步驟很重要,因為這樣才能確保訓練資料的label品質。
訓練資料的處理技巧
針對訓練資料,在放入Bert模型訓練前,還有一個地方要注意,就是Bert最常只能夠接收512個字,當作一筆文本的input。但是大多時候,我們的文章,往往都超過512個字。最簡單地作法,就是直接將文章進行truncate,取前面512個字,但是這樣文章的後面,就沒辨法讓模型學習,所以有另外一個比較好的作法,是將一篇文章,切割成一段一段。例如以一個句點作為切割點。有一些為了增加文句的變化性,也可以用sliding window的方式,將一整段文句,透過slide的方式,生成頭尾和前後段文句都會over-lapping的input。
另外一個常見需要處理的問題,就是整段句子中,都沒有需要被highlight的類別,針對這類句子,就是常見的負樣本,這種樣本通常會比正樣本數量多出非常多,因此在訓練中,可以剔除部份的負樣本,這樣可以減輕在訓練中imbalanced data的狀況,讓模型可以學的更好。
如何提升少數樣本的類別準確度
在分類文本中,一定會有一些類別,因為它的樣本特別少,導致它的分類準確度會下降很多,這時,可以透過confusion matrix的方式,觀察模型到底是在哪幾類別上的分類效果特別差,因此需要針對這些類別的樣本,再進行加工,不論是直接重複製該類別樣本,增加訓練集數量,或是人工製作假的該類別樣本,來讓模型更多機率接觸這類的類別,可以真正地學習到如何正確分類少樣本的類別。
最後成果
原本這個專題在使用Bert為主的NER模型訓練時,會發現模型對於負樣本的分類正確度非常高(因為imbalanced data的狀況),但正樣本的正確度不夠高。因此在這過程中,就經歷了重新整理類別的數量,並且針對訓練的樣本,進行正樣本的over-sampling,還有將文章樣本,改以句子的方式(將句子截短),作為一個個input,最後讓整體的模型預測達到了97%的正確率,並且也能夠正確辨別出稀少類別。
心得小結
在這兩個案例中,我們探討了幾個建置AI模型的重要觀念,針對結構型資料本身,如何妥善清理與整併資料;針對非結構型的文字訓練資料,如何透過適當的段落切割,就可以強化預訓練模型Bert適應新文本的能力。遇到不平衡資料時,如何透過手動over-sampling的方法,減輕不平衡資料對模型學習效果的影響。當完成模型訓練時,可以使用哪些工具,來解釋模型,找尋真正影響產出的關鍵因子。最後當然還是再一次強調,人工智慧科學家也需要和該問題領域的domain expert合作,一起來建構模型,這樣所產出的模型,往往會比直接一股地使用複雜的模型,丟入大量未經整理的資料,準確度來得高,該模型也會比較精簡,容易解釋與使用。
- 主辦暨執行單位:
財團法人台灣人工智慧學校基金會 - 協辦單位:
中央研究院資訊科學研究所、中央研究院資訊科技創新研究中心 - 捐助企業:
台塑企業、奇美實業、英業達集團、義隆電子、聯發科技、友達光電、新光人壽-新壽管理維護
Copyright© 台灣人工智慧學校 | Taiwan AI Academy 版權所有