YOLOv4 產業應用心得整理 - 張家銘
 YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection2020 年在 AI 領域中有不少令人振奮的技術創新,像是在電腦視覺領域的 YOLO v4 以及自然語言領域的 GPT-3,而 YOLO (You Only Look Once) 為物件偵測 (Object Detection) 的重要技術。
YOLO 首次於 2015 年 6 月由 Joseph Redmon 提出,隨著時間推進又推出了 YOLOv2 (2016.12)和 YOLOv3 (2018.04),而在 2020.02.21 時 YOLO 之父 Joseph Redmon 宣布退出電腦視覺領域,但是這並不影響 YOLO 的進化,在 2020 年 4 月時就推出了 YOLOv4,總共有三位作者,第一個是來自俄羅斯的 Alexey Bochkovskiy,他曾經參與 YOLO github 的項目維護,而另外兩位則來自台灣,分別是中央研究院資訊所的廖弘源所長與王建堯博士,YOLOv4 在 AI Rewind 2020: A Year of Amazing Papers 榮獲 2020 年度最驚艷的論文之一,簡直是 AI 界的台灣之光。
那麼紅的 YOLOv4 想必大家都在使用,在我們台灣人工智慧學校技術領袖班的結業專題中,使用的組別也是大有人在。在本篇文章中,將整理一些使用 YOLOv4 的心得 : (關於技術細節方面並不會深入探討)
- 物件偵測能應用在哪裡
- YOLOv3 和 YOLOv4 差異
- CFG 說明 (超參數)
- 人臉偵測的 YOLO 模型
- 模型部屬
- 使用 YOLOv4 時常見的狀況
- 結語
物件偵測能應用在哪裡
物件偵測在現實生活中可以解決許多問題,例如
- 瑕疵偵測:製造業常用的瑕疵檢測
- 社交距離+口罩偵測:目前疫情下的口罩偵測以及維持社交距離
- 人臉偵測:進一步可以發展為人臉辨識,進而實現人臉打卡、罪犯追蹤
- 交通路況偵測:促進智慧交通的發展,像是車流或是人流偵測
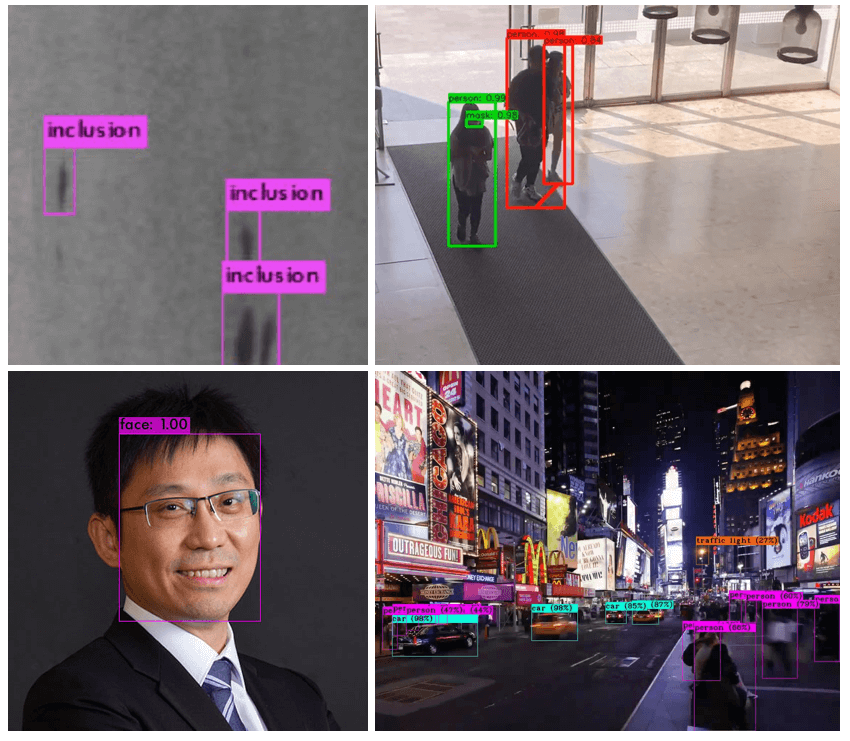 來源:立達軟體科技股份有限公司、長庚大學、中研院
來源:立達軟體科技股份有限公司、長庚大學、中研院YOLOv4 展示影片如 影片一 所示:
影片一,YOLOv4 展示影片
YOLOv3 和 YOLOv4 差異
YOLOv3 發表於 2018 年 4 月,讓我們來看看經過兩年後 YOLO 進化成怎樣吧!
在 圖一 和 圖二 中,分別畫出了 YOLOv3 和 YOLOv4 的網路架構圖,方便比較兩者的不同
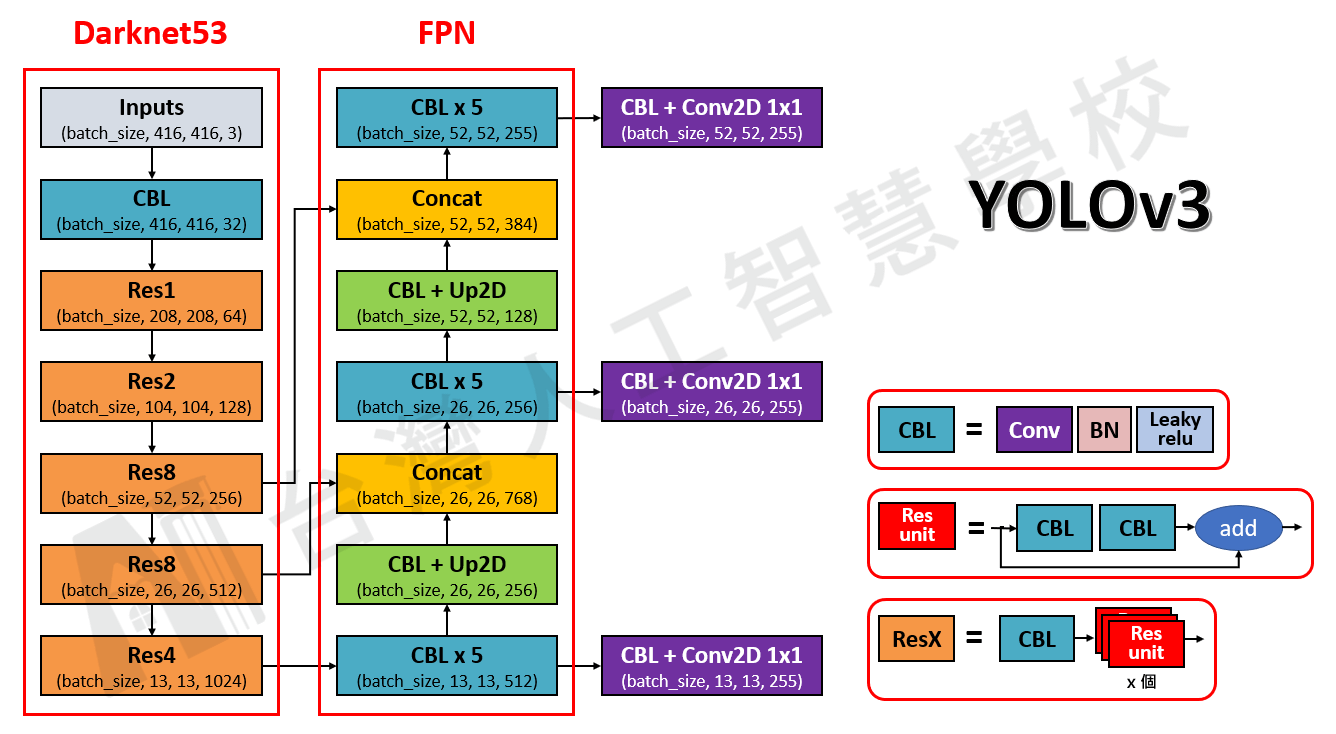 圖一,YOLOv3 網路架構圖
圖一,YOLOv3 網路架構圖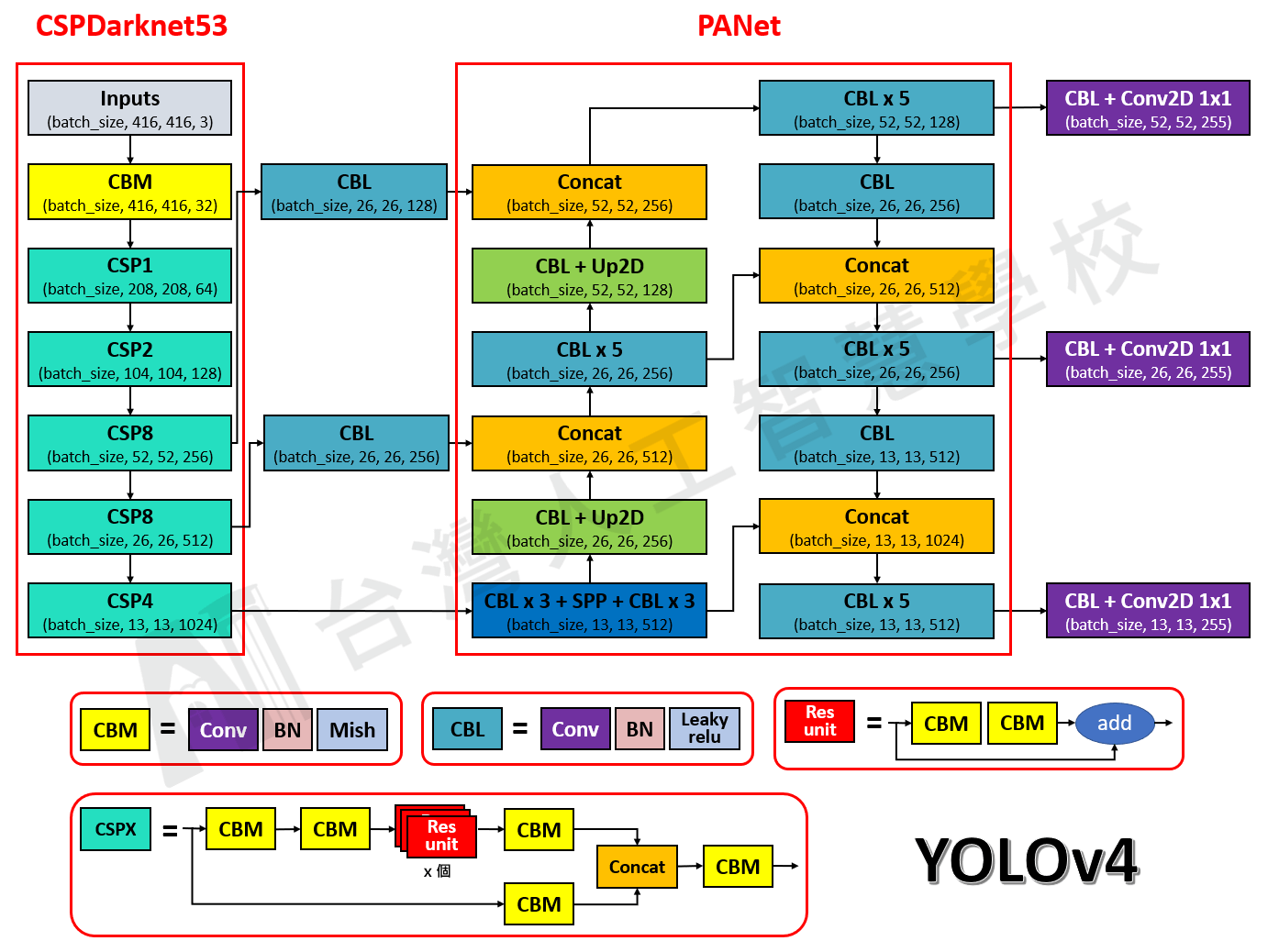 圖二,YOLOv4 網路架構圖
圖二,YOLOv4 網路架構圖我們可以從圖中清楚的看到兩者的區別,另外我將它們的差異整理在 表格一 中
表格一,YOLOv3 和 YOLOv4 差異
YOLOv3 | YOLOv4 | 為什麼要這樣改進 | |
|---|---|---|---|
| Backbone | Darknet53 | CSPDarknet53 | 參數量減少,進而減少運算量,甚至能提高準確率 |
| Neck | FPN | PANet + SPP | 提升局部特徵和全局特徵的融合,進而豐富最終特徵圖的表達能力 |
| Head | YOLO | YOLO | None |
| Activations | leaky-ReLU | leaky-ReLU + Mish | Mish 的梯度更平滑,可以穩定網路梯度流,具有更好的泛化能力 |
| Bounding box regression loss | MSE loss | CIoU-loss | 使得訓練和推論時用的驗證標準一致,並且能更好的學習 Bounding box |
| Data Augmentation | Pixel-wise adjustments | Mosaic | 由 4 張影像拼成 1 張影像,增加了許多小目標,且 Mini-batch 減少 4 倍,進而減少 GPU 的計算 |
| Regularization | Dropout | DropBlock | 由於圖片是連續的,所以選擇隨機 dropout 掉一整個區域 |
| Normalization | Batch Normalization (BN) | Cross mini-Batch Normalization (CmBN) | 可以更好的適用於小的 batch size 上 |
| Attention Module | None | Spatial Attention Module (SAM) | 增加注意力機制,使得不會因為網路的加深而忘記前面的訊息 |
| Loss function trick | None | Class label smoothing, Grid Sensitivity | 解決在 Grid 邊緣時較難偵測到的問題 |
假如讀者想要了解細節,可以參考以下的文章連結,這邊就不多加撰述了:
- YOLOv3: YOLO演進 — 2 — YOLOv3詳細介紹
- YOLOv4: YOLO演進 — 3 — YOLOv4詳細介紹
CFG 說明 (超參數)
常見的深度學習框架是 TensorFlow 和 PyTorch,而 YOLO 作者基於 C 和 CUDA 寫了一個相對小眾的深度學習框架 — Darknet,優點是易於安裝,以下提供了一些 source code 可以訓練 YOLO 模型,詳細訓練說明可以查看 github。
- Darknet — https://github.com/AlexeyAB/darknet
- TensorFlow — https://github.com/hunglc007/tensorflow-yolov4-tflite
- PyTorch — https://github.com/WongKinYiu/PyTorch_YOLOv4
在使用 darknet 訓練時可以根據更改 CFG,來調整自己的需求,有關 CFG 的說明可以參考下列說明
- CFG Parameters in the [net] section
- CFG Parameters in the different layers
在這邊我會列幾個比較重要的超參數,並解說一下它的重要性
Inputs:
- batch: 就是常見的 batch size,一次丟 batch size 筆的資料給模型訓練
- subdivisions: 若 GPU 記憶體不夠的話可以調整這個參數,mini_batch = batch/subdivisions,而 mini_batch 才是實際送進去訓練的 batch
- width: 影像的寬
- height: 影像的高
Data augmentation:
- angle, saturation, exposure, hue, blur: 基本的資料擴增方法
- mosaic: 在 YOLOv4 提出的方法,可以將四張影像拼成一張,進而減少運算量和增加小物體目標
- letter_box: 保持長寬比,通常我們希望物體不要有變形,因此都會讓它保持長寬比
Optimizer:
- policy: 學習率的動態調整策略包含: constant, sgdr, steps, step, sig, exp, poly, random,詳細如何使用請參考上面的連結,預設的話是使用 steps 這個策略:steps 和 scales 是綁在一起的,steps=400000,450000、scales=.1,.1 的意思是在第 400000 和 450000 時各將學習率乘以 0.1
- label_smooth_eps: 使用 label smoothing 的參數
yolo layer:
- mask: anchors 的 index,每層 yolo layer 會選擇 3 個 anchors
- anchors: YOLO 算法中一個很重要的東西,anchor-based 的物件偵測方法都會使用到,在 darknet 中可以使用 calc_anchors 透過 k-means 來根據訓練資料聚合出指定類別數的 anchors,值得一提的是每層 yolo layer 需要 3 個 anchor,而 YOLOv4 有三層 yolo layer 因此需要聚合出 9 個 anchor,另外 YOLOv4-tiny 比較輕量,所以只有兩層 yolo layer 因此只需聚合出 6 個 anchor,作者也有提供 YOLOv4-tiny 三層 yolo layer 的版本。
- ignore_thresh: 若預測的 Bounding box 和 Ground truth 的 IoU 大於此參數,則納入 loss 的計算,通常用 0.5~0.7
- scale_x_y: 用來防止 Eliminate grid sensitivity 的問題
- iou_loss: 有 mse, giou, diou, ciou 可以選擇,YOLOv4 使用了 ciou 取代了 mse 來當作計算 BBOX 的 loss
- random: 代表每 10 次迭代輸入影像會隨機縮放到 x/1.4~1.4x,這樣在推論時才可以適應各種影像的尺寸。
人臉偵測的 YOLO 模型
在這邊我使用了官方提供的 darknet 來訓練一個人臉偵測模型,人臉資料集選用 WIDER FACE Dataset 共有 32203 張圖像其中包含 393703 個人臉目標,分別在尺度、姿勢、標準、表情、裝扮和光照有不同的表現,如 圖三 所示,其中 40% 為訓練集、10% 為驗證集、50% 為測試集。
 圖三,wider face dataset
圖三,wider face dataset而我分別使用 YOLOv3 和 YOLOv4 去訓練,各用兩顆 GPU 的訓練時間分別是 14.5 小時和 17 小時, YOLOv4 的訓練時間雖然比較長,但是比起 YOLOv3 偵測人臉的效果好很多 (在 圖四 中可以看到在 mAP 這個評估指標下 YOLOv3 最高的 mAP 是 61%,而 YOLOv4 比 YOLOv3 高了 7.5% 來到了68%),這個關鍵在於說 YOLOv4 在訓練時增加了很多 YOLOv3 沒有使用到的技巧。
mAP介紹:深度學習系列: 什麼是AP/mAP?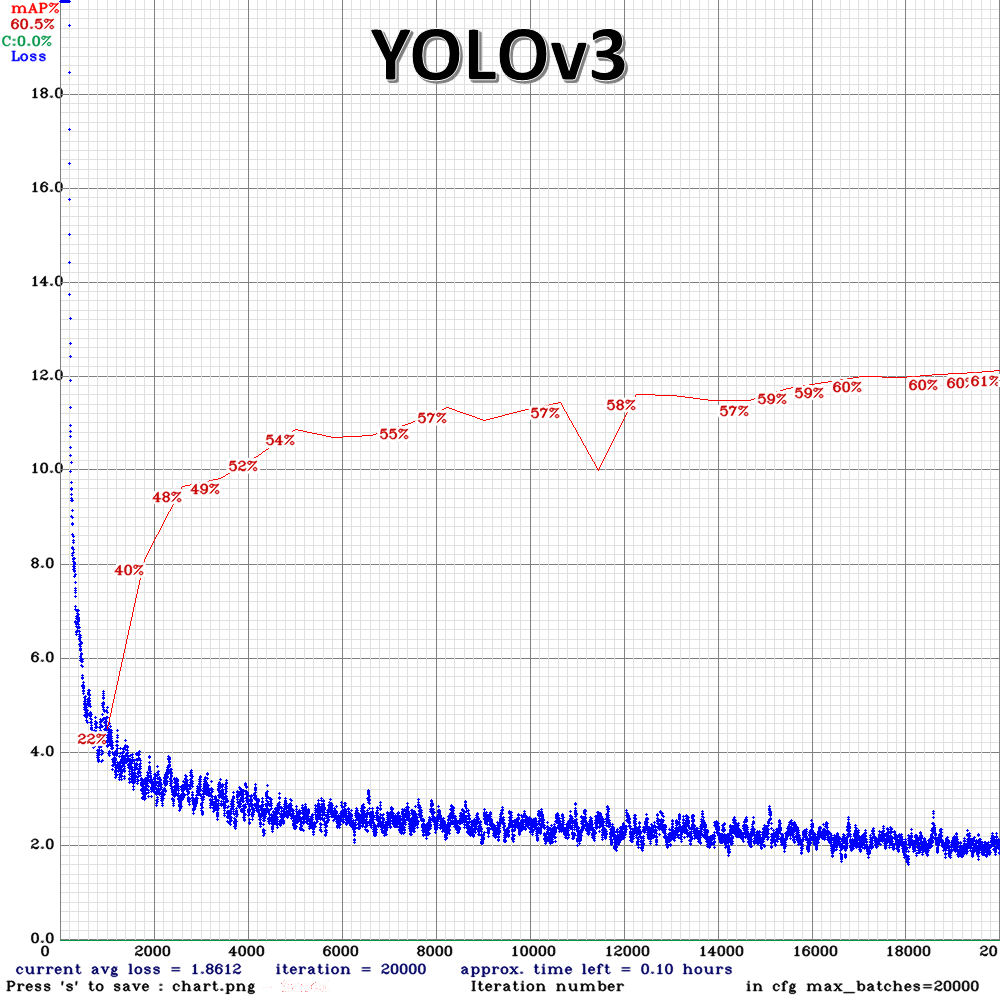 圖四,YOLOv3 和 YOLOv4 的 training history 之 1
圖四,YOLOv3 和 YOLOv4 的 training history 之 1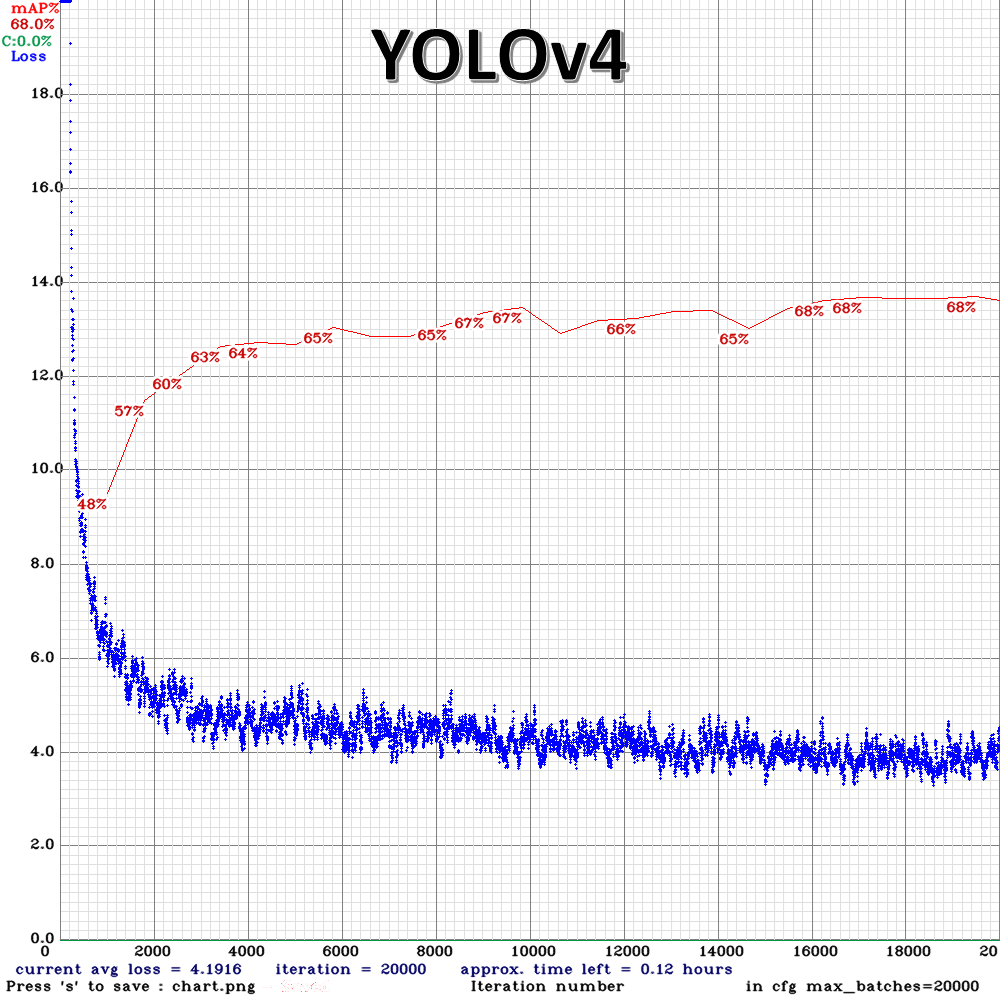 圖四,YOLOv3 和 YOLOv4 的 training history 之 2
圖四,YOLOv3 和 YOLOv4 的 training history 之 2另外我實際推論了一個在菜市場邊走邊錄影的影片,如 影片二 所示。可以觀察到他們兩個模型的效果其實都很好,但如果仔細觀看的話可以發現 YOLOv4 連特別小的人臉都可以偵測出來,很仔細的話...
影片二,YOLOv3 和 YOLOv4 在影片的推論比較
在 圖五 這張照片的比較中,乍看之下好像沒什麼區別,但是如果認真看的話在小目標上 YOLOv4 會把臉框的更精準,看不清楚沒關係,我們放大左上方的位置來比較看看,結果如 圖六 中所示,可以看到 YOLOv4 會把人臉包覆的更好
 圖五,YOLOv3 和 YOLOv4 在照片的推論比較
圖五,YOLOv3 和 YOLOv4 在照片的推論比較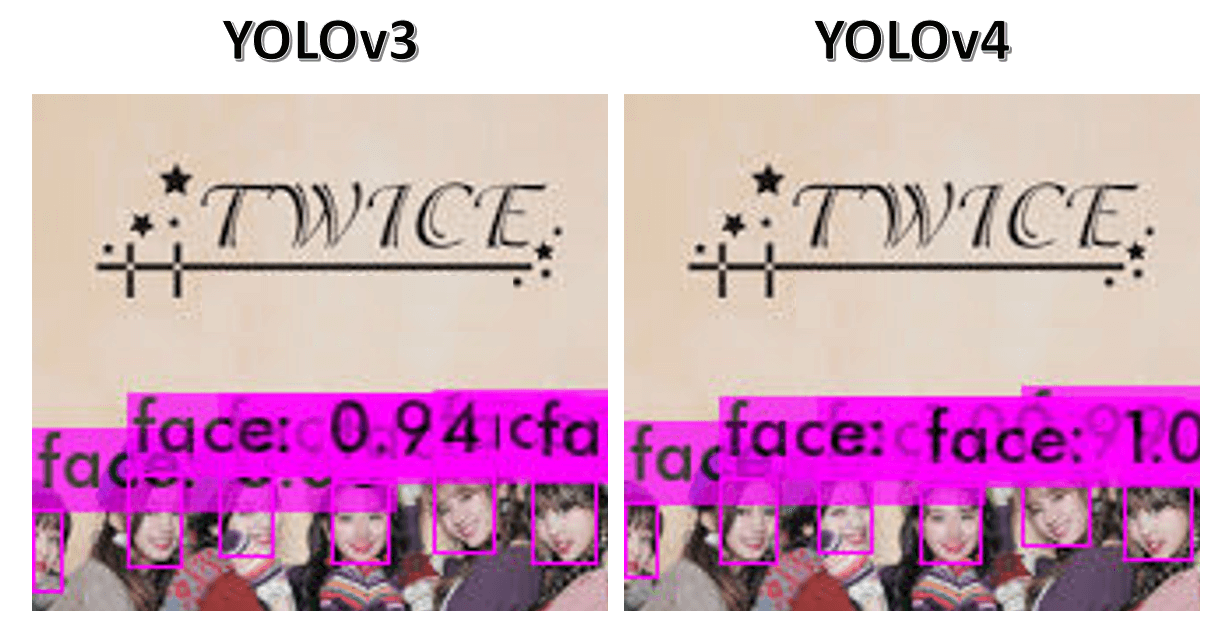 圖六,放大 圖五 左上方的畫面
圖六,放大 圖五 左上方的畫面模型部屬
近幾年來的 AI 落地最火紅的應該就是 Edge AI,在 圖七 中我們可以看到 Edge AI 在最頂端的地方
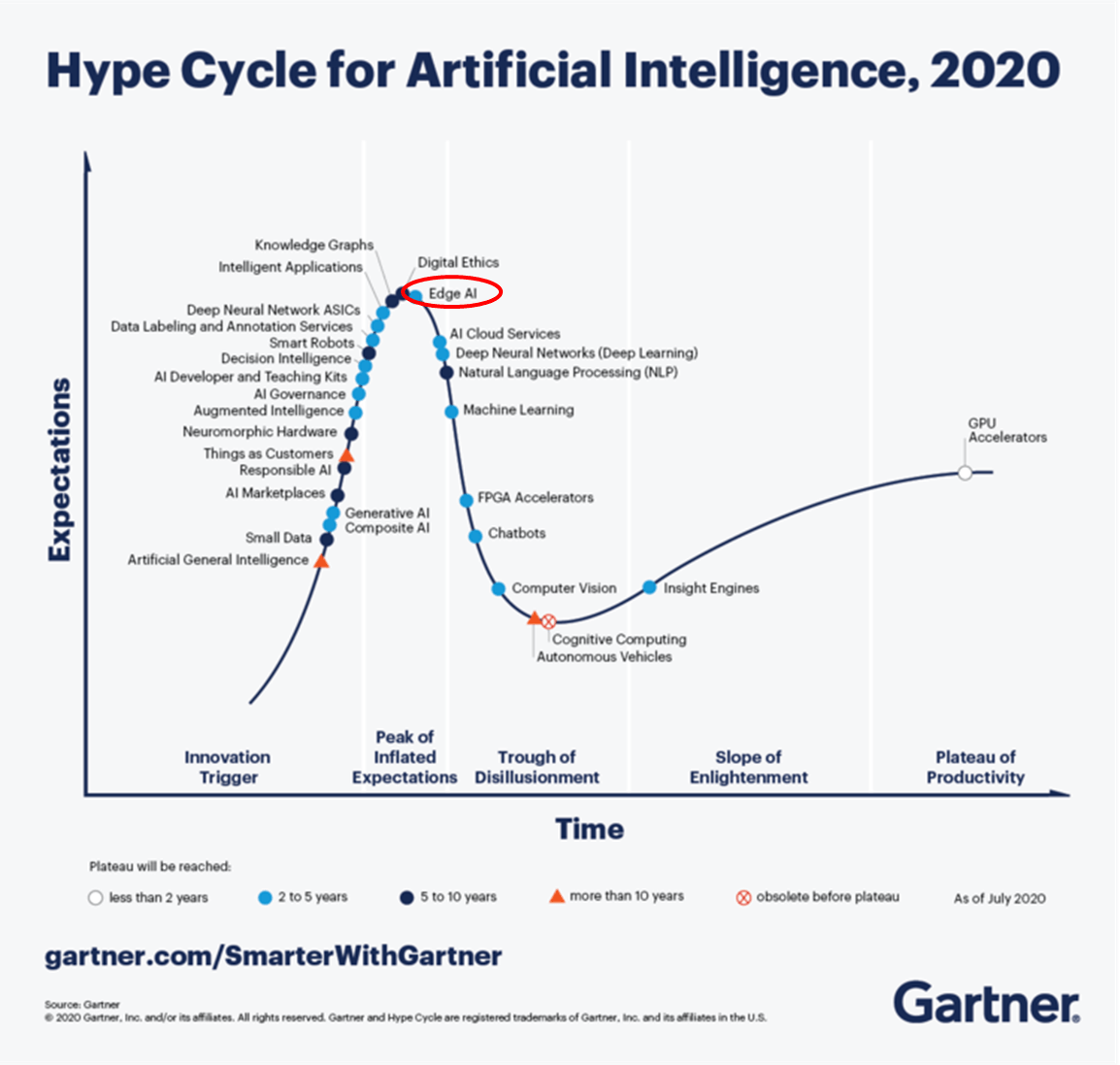 圖七,Hype Cycle for AI in 2020
圖七,Hype Cycle for AI in 2020我們在訓練模型通常是在 Cloud 端上訓練,人們想著模型架構越大準確率越高越好,而想在 Edge 端上運行 AI 模型並實現 real time 就會受運算資源影響,因此需要模型架構小且推論速度快的模型,因此在 2020 年 11 月又推出了 Scaled-YOLOv4,他能讓你選擇要準確率還是要推論速度。
若要求準確率可以選擇在 Cloud 端上運行 YOLOv4-large 模型: YOLOv4-P5, YOLOv4-P6, YOLOv4-P7,在 圖八 中可以觀察到 YOLOv4-large 的 AP (綠色的線) 都比 YOLOv4 (灰色的線) 要好
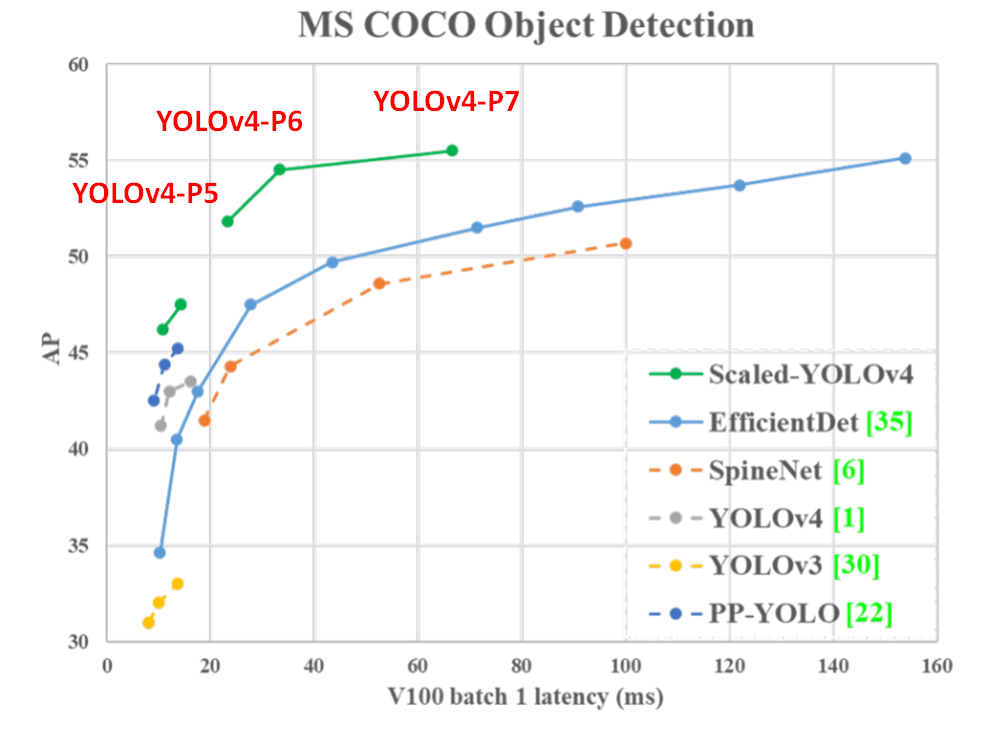 圖八,YOLOv4-large performence
圖八,YOLOv4-large performence若要求速度可以選擇在 Edge 端上運行 YOLOv4-tiny 模型,作者在不同 Nvidia GPU 設備中測試 YOLOv4-tiny 的速度,包括 Xavier AGX, Xavier NX, Jetson TX2, Jetson NANO,在 表格二 中比較了 FP32 的精度和 FP16 的精度的推論速度,在 NANO 中 FP32 的 FPS 為 16,而 FP16 的 FPS 可以達到 39,可以看到速度大概差了兩倍多
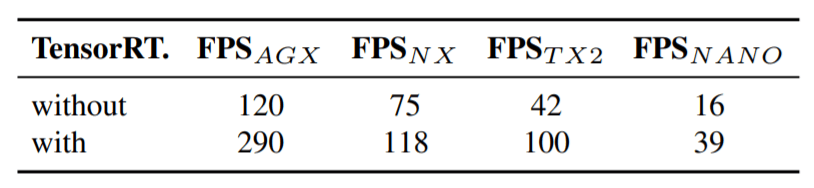 表格二,
表格二,影片三 是我實際使用 Jetson Nano 並用 FP16 的精度經由 TensorRT 加速後的結果,可以看到在預測單個人時可以高達 39 FPS,並且 YOLOv3-tiny 和 YOLOv4-tiny 的推論速度沒有太大的差異
影片三,YOLOv4-tiny on Jetson nano除了官方提供的 tiny 系列,有些非官方的甚至提出了可以在 CPU 上達到 Real time 速度的 YOLO 模型,在這邊列給各位參考,當然在準度方面就不能太要求,在準度和速度方面需要自己取捨:
- Yolo-Fastest: https://github.com/dog-qiuqiu/Yolo-Fastest
使用 YOLOv4 時常見的狀況
- 由於預設 cfg 的 anchors 是使用 coco datasets 計算出來的 anchors,在訓練自己的資料集時不一定適用,因此需要使用 calc_anchors 來計算出適合自己 datasets 的 anchors。
- 如果是在類似 colab 這種不能有彈出式視窗的環境下訓練時,後面記得要加 -dont_show,不然會報錯,例如:
$ darknet detector train data/coco.data data/yolov4-coco.cfg data/yolov4-csp.conv.142 -dont_show
- 當發生類別不均衡時可以使用 GAN 的方法來自己生成數量較少的資料,例如在瑕疵檢測中,一定有一些瑕疵是很少出現的,這時候可以使用 segmentation 的方法將瑕疵切出來再貼到想要貼上去的背景影像,若想要將其更無違和的貼上去可以使用 GP-GAN 的方法,如 圖九 所示。
 圖九,GP-GAN 達成無違和合成
圖九,GP-GAN 達成無違和合成 - 當你開始訓練了,結果只訓練一下就斷掉有 segmentation fault (core dumped) 的情形發生,這時會生成出 bad.list ,裡面會記錄一些不正常的訓練檔案,例如你的 x, y, w, h 有 ≤ 0 的狀況,更正後就可以訓練了。
- 若訓練完模型,想在 Python 中做進一步的應用,可以使用 opencv 來 load YOLOv4 的 weights 和 cfg 檔,範例 code 如下:
import cv2 CONFIDENCE_THRESHOLD=0.2 NMS_THRESHOLD=0.4 net = cv2.dnn.readNet("yolov4.weights", "yolov4.cfg") model = cv2.dnn_DetectionModel(net) model.setInputParams(size=(416, 416), scale=1/255, swapRB=True) classes, scores, boxes = model.detect(img, CONFIDENCE_THRESHOLD, NMS_THRESHOLD)YOLOv4 inference using OpenCV DNN - 在 edge 端上用 yolov4-tiny-3l.cfg 的 mAP 比 yolov4-tiny.cfg 高,可以觀察到 3 層 yolo layer 在偵測小物體上還是很有用的。令人驚訝的是推論的速度居然沒有差多少,讀者可以考慮使用 yolov4-tiny-3l.cfg 來應用在 edge 端上。而再進一步的使用四層 yolo layer 時效果並沒有比三層的好,看來在這個人臉偵測的任務中三層 yolo layer 就足夠了。
結語
YOLOv4 是個簡易上手又效果很好的工具,在很多產業應用上都可以使用它來解決問題,例如在製造業上可以偵測出有異常的產品、在農業上可以偵測出水稻的位置,進而估算出收穫量、在當今疫情下可以偵測出人臉,並搭配熱影像溫度偵測來判斷進出人員有無發燒、在智慧交通上可以偵測出車輛或行人的流量,進而控制紅綠燈的秒數,讓交通更有效率!看了那麼多案例,心動不如馬上行動,還沒用過的快來試試看吧!
而近年來不同於 anchor-based 的物件偵測方法也開始雨後春筍般地冒出,例如 anchor-free 的方法、基於 Transformer 的方法,若對其他實現物件偵測的方法有興趣的話也可以去查看看哦
Reference
- 主辦暨執行單位:
財團法人台灣人工智慧學校基金會 - 協辦單位:
中央研究院資訊科學研究所、中央研究院資訊科技創新研究中心 - 捐助企業:
台塑企業、奇美實業、英業達集團、義隆電子、聯發科技、友達光電、新光人壽-新壽管理維護
Copyright© 台灣人工智慧學校 | Taiwan AI Academy 版權所有