最新的物件偵測王者 YOLOv7 介紹

王建堯博士、Alexey Bochkovskiy 與廖弘源所長在 2020~2021 年間相繼推出了 YOLOv4, ScaledYOLOv4, YOLOR,而在今年七月初推出了最新力作 - YOLOv7,它在 5 FPS ~ 160 FPS 範圍內的速度和準確度都超過了所有已知的物件偵測器,像是基於 Transformer 的 SWIN-L-Cascade-Mask R-CNN、基於卷積的 ConvNeXt-XL, Cascade-Mask R-CNN、YOLO 系列的 YOLOv4, Scaled-YOLOv4, YOLOR, YOLOv5, YOLOX, PPYOLO、還有 DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B 等,如 圖一 所示。
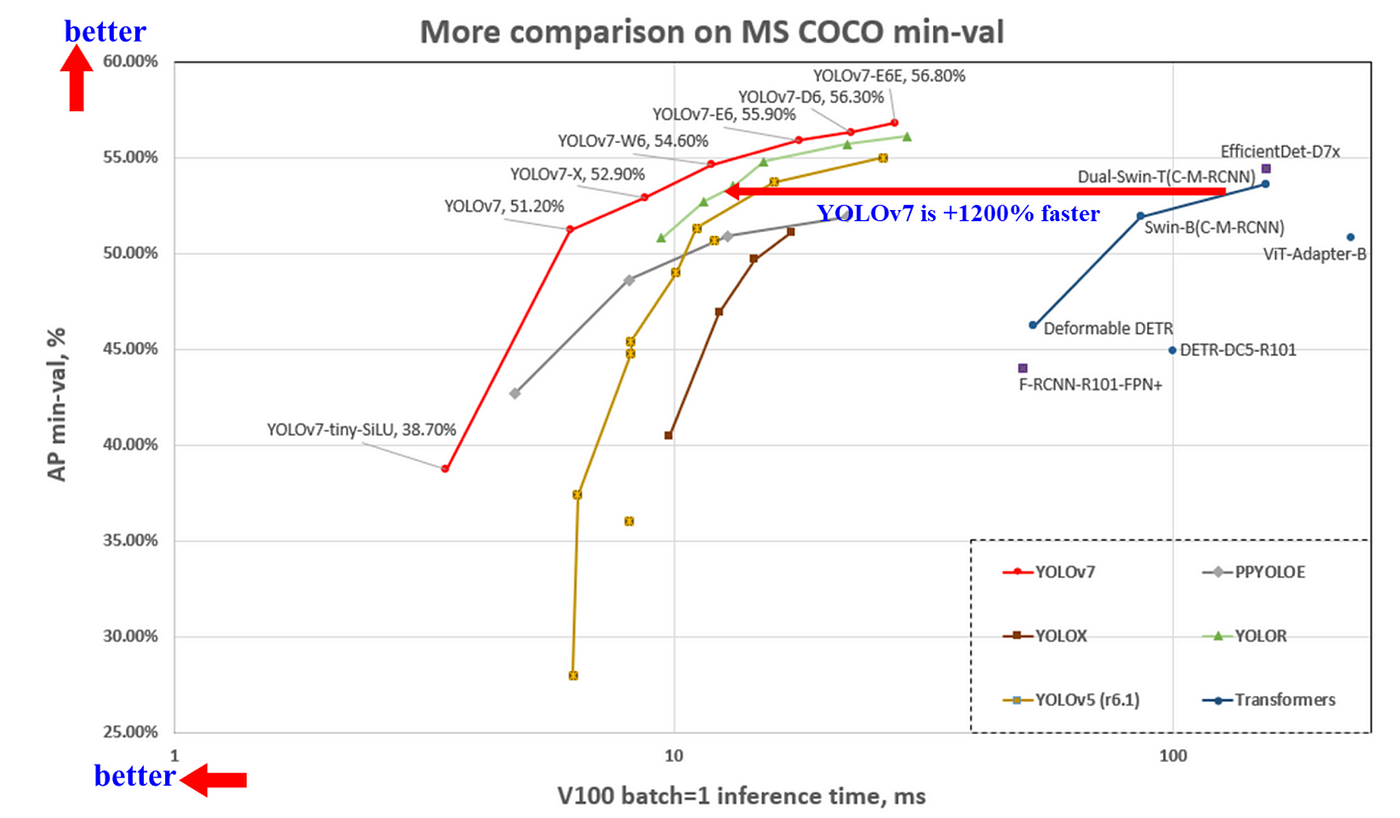
YOLOv7 減少了當今 real-time object detection sota 約 40% 的參數量和約 50% 的運算量,主要分成兩個方面去優化:模型架構優化和訓練過程優化,針對模型架構優化,作者提出了有效利用參數和運算量的 extended 和 scaling 方法,而針對訓練過程優化,在 YOLOv4 中將 “以增加訓練成本為代價提高準確度,但是不會增加推論成本的模塊或方法”,稱為 bag-of-freebies,在 YOLOv7 中使用 re-parameterized (重參數化) 技術替換原始的模塊和使用 dynamic label assignment (動態標籤分配) 的策略,其功用能將 label 更有效率的分配給不同的輸出層。
以下就讓我們來細看這些優化方法:
模型架構優化
1. Extended efficient layer aggregation networks (擴展的高效層聚合網路)
CSPVoVNet [1] 圖二(b) 是基於 VoVNet [2] 圖二(a) 圖二之一 變化而來,其在設計架構時除了考慮參數量、運算量、計算密度等因素外,還分析了梯度路徑,使得不同層的權重能夠學習到更多多樣性的特徵,使得推論速度更快、準確率越高。
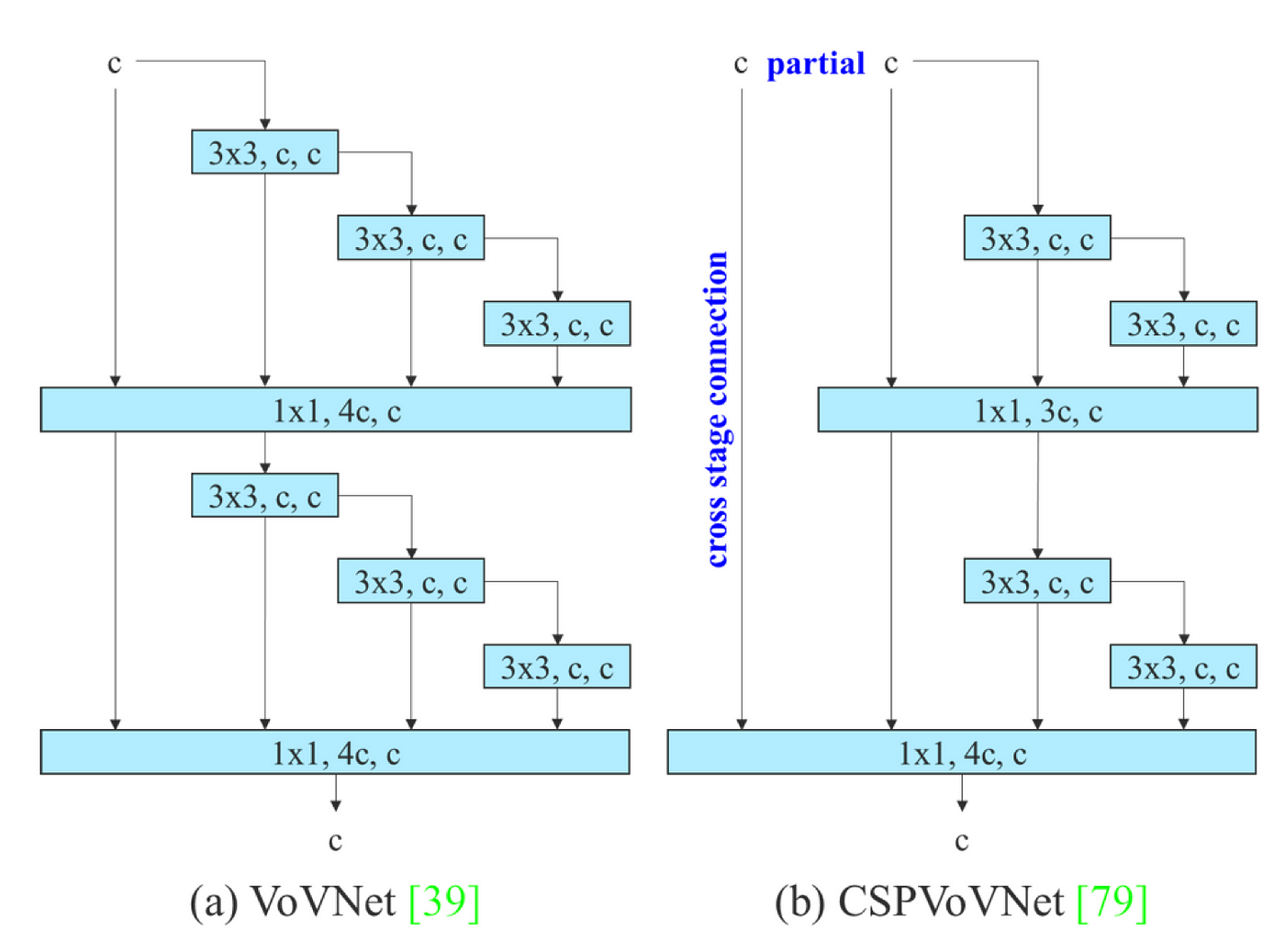

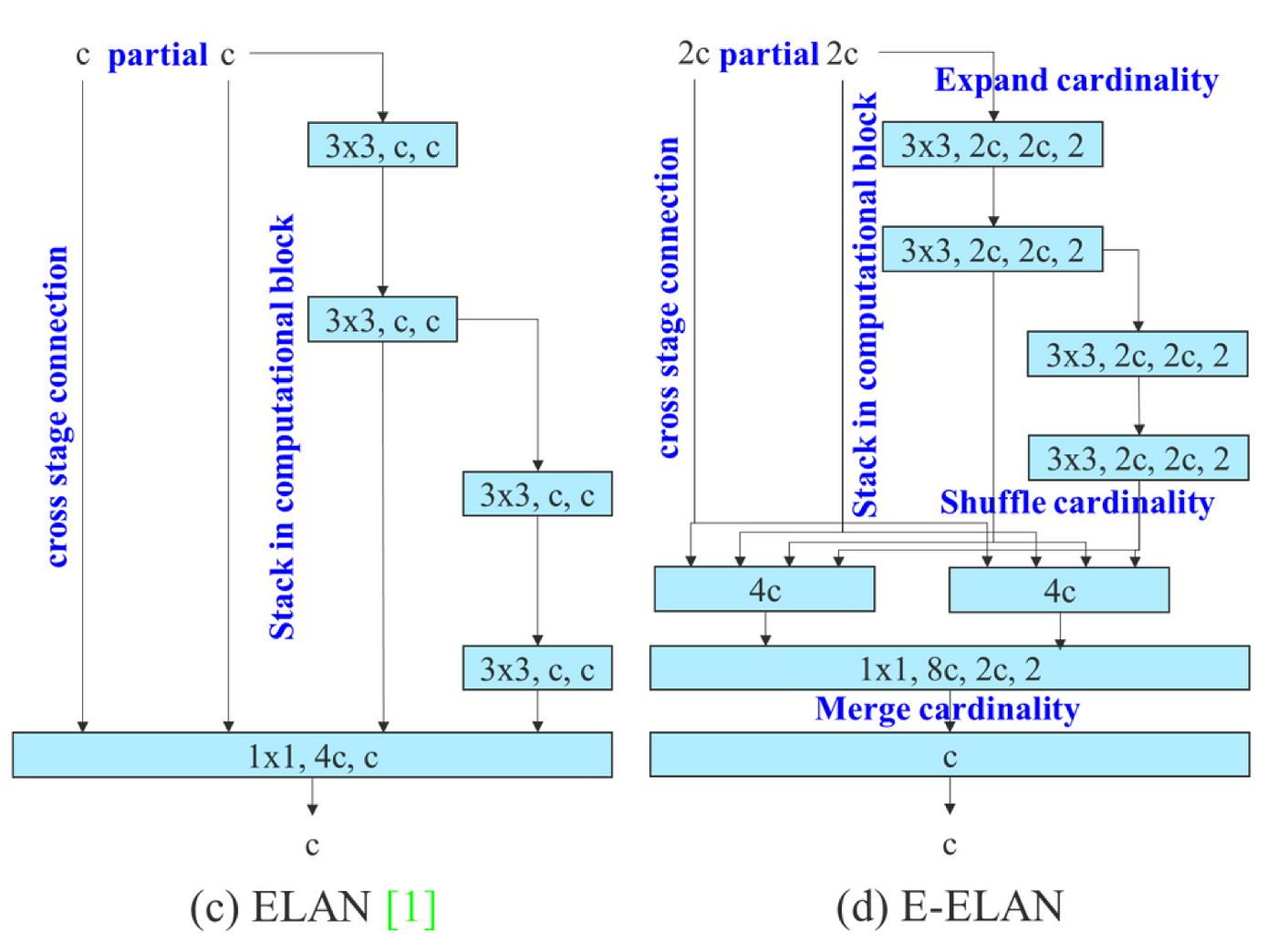
而 ELAN [3] 圖二(c) 通過控制最短和最長的梯度路徑來讓越深的網絡可以更有效的學習和收斂,由於如果堆疊更多的模塊可能會破壞這種穩定的狀態,因此 YOLOv7 提出了 extened ELAN (E-ELAN) 圖二(d),它透過 expand cardinality, shuffle cardinality, merge cardinality 等手法來達到不破壞梯度路徑狀態,並能持續增強網路學習能力的效果。
2. Model scaling (模型縮放)
透過將設計好的模型進行縮放,可以進一步適用於不同運算設備,模型縮放方法通常使用不同的縮放因子,例如 resolution(輸入影像的大小)、depth(網路的層數)、width(特徵圖的通道數)和 stage(特徵金字塔的數量),以便在網路的參數量、運算量、推論速度和準確率方面取得良好的 trade-off,例如 EfficientNet [4] 考慮了 resolution, depth, width,而 Scaled-YOLOv4 則是調整了 stage。
Doll‘ar [5] 等人分析了卷積和群卷積對參數量和運算量的影響,並根據研究設計了對應的模型縮放方法,這些方法都是應用在諸如 PlainNet 或 ResNet 這樣類型的架構,這些架構在 scaling up (調大 resolution, depth, width, stage 等)或 scaling down (調小 resolution, depth, width, stage 等) 時,每層的輸入和輸出寬度並不會改變。
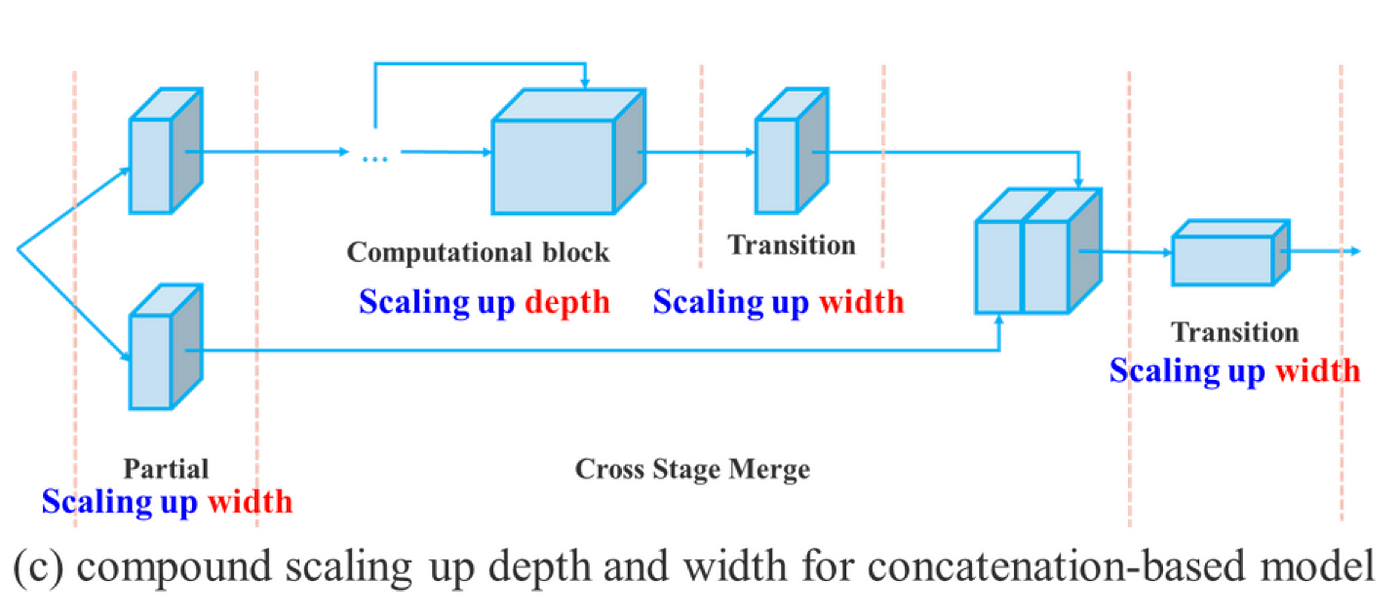
而在 concatenation (串聯) 模型 (如 VoVNet) 的模型縮放中,若對 Depth 進行 scaling up 或 scaling down 時,後面的 transition layer 的輸入寬度將會隨之增加或減少,進而導致設計好的模型在運算硬體上使用率下降,如 圖三(a) 到 (b) 所示:

因此,作者提出 compound model scaling (複合模型縮放) 方法如 圖三(c),即對 concatenation-based 的模型進行模型縮放時,只需要對 computational block 中的 depth 進行縮放,其餘的 transition 進行相應的寬度縮放,就能夠維持初始模型在設計時擁有的性質,以維持最佳的結構。
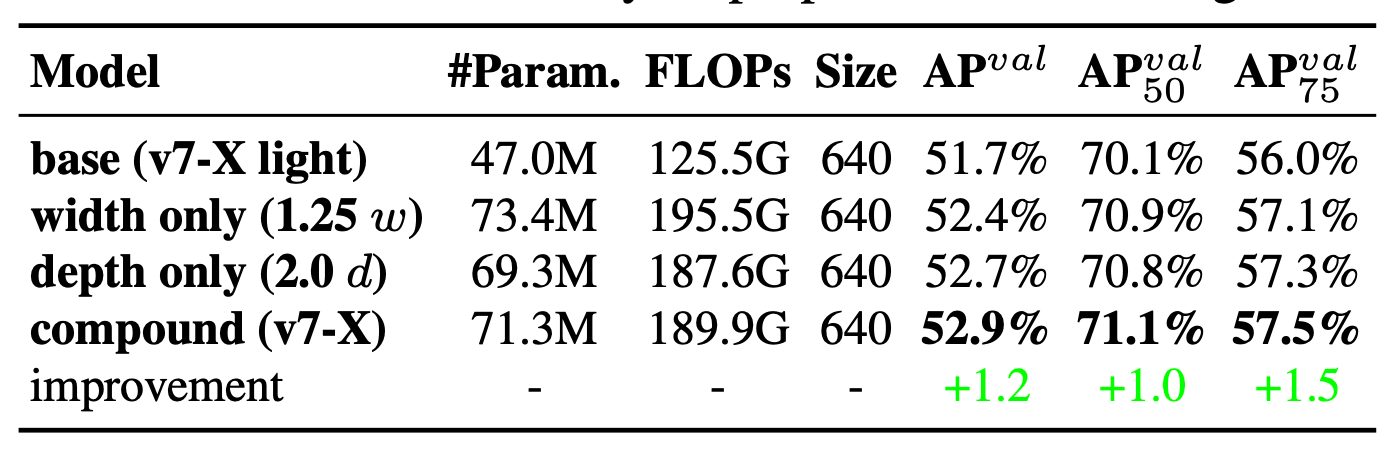
在 表一 中,可以看到使用 model scaling 技術可以提高準確率,若單純將 width 放大 1.25 倍可以提昇 0.7% AP,若單純將 depth 放大 2 倍則可以提昇 1% AP,若進一步使用 compound model scaling:depth 放大 1.5 倍,width 放大 1.25 倍可以提升最多準確率,高達 1.2% AP。
訓練過程優化 (Bag-of-freebies)
1. Model re-parameterized (模型重參數化)
模型重參數化技術可以看做是一種 ensemble (集成) 技術,我們可以將其分為兩大類,即 model-level (模型級) 和 module-level (模塊級):
- model-level 模型級重參數化
有兩種常見做法,一種是用不同的訓練資料來訓練多個相同的模型,然後對多個訓練模型的權重進行平均。另一種是對不同迭代次數的模型權重進行加權平均。
- module-level 模塊級重參數化
這種方法為近期比較流行的研究問題,它會在訓練過程中將一個模塊拆分為多個相同或不同的模塊分支,並在推論過程中將多個分支模塊集成為一個完全等效的模塊。然而,並非所有提出的重參數化模塊都可以完美地應用於不同的架構。考慮到這一點,YOLOv7 開發了新的重參數化模塊,並設計了適用於各種架構的重參數化模塊策略。
RepConv [6] 是一個著名的模型重參數化方法之一,它在訓練時將 3x3 卷積、1x1 卷積和 identity connection (id) 組合在一個卷積層中,而在推論時將他重組成一個 3x3 的卷積,這個方法在 VGG 架構上取得了優異的性能,如 圖四 所示。
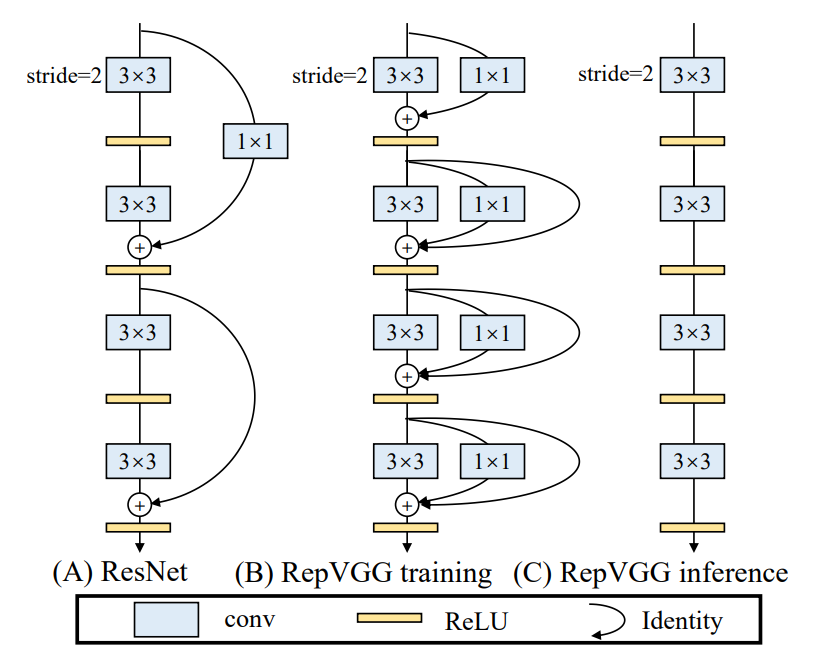
然而,當作者直接將 RepConv 應用於 ResNet 和 DenseNet 等架構時,其準確率反而會顯著降低,在分析了 RepConv 和不同架構的組合和對應性能後,發現 RepConv 中的 id 會破壞 ResNet 中的 residual 和 DenseNet 中的 concatenation 特性:為不同特徵圖提供了更多梯度多樣性。
因此作者認為具有 residual 或 concatenation 架構的卷積層應用重參數方法重組架構時不應含有 id,如 圖五 所示,可以看到由於 (a) 本身沒有 residual 或 concatenation 特性,因此可以直接應用 RepConv 變成 (b),而 (c) 本身含有 residual 特性,因此在應用 RepConv 後 (d) 反而會導致準確率降低。
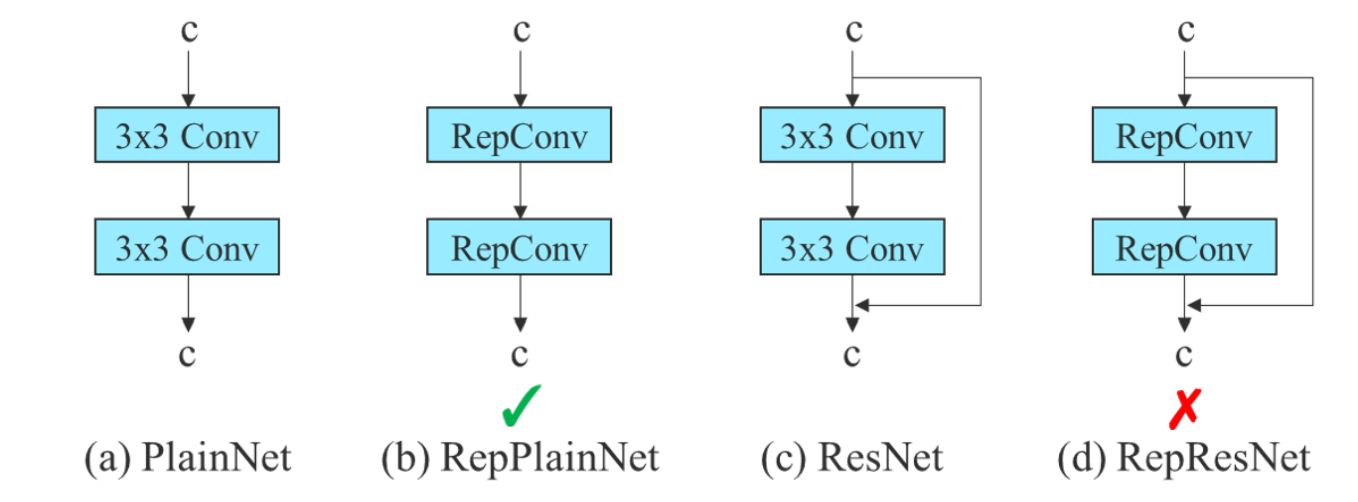
由於上述原因,作者使用沒有 id 連接的 RepConv (稱為 RepConvN) 來設計重參數化卷積的架構。圖五 顯示了作者設計的 planned re-parameterized convolution 用於 ResNet 的範例。

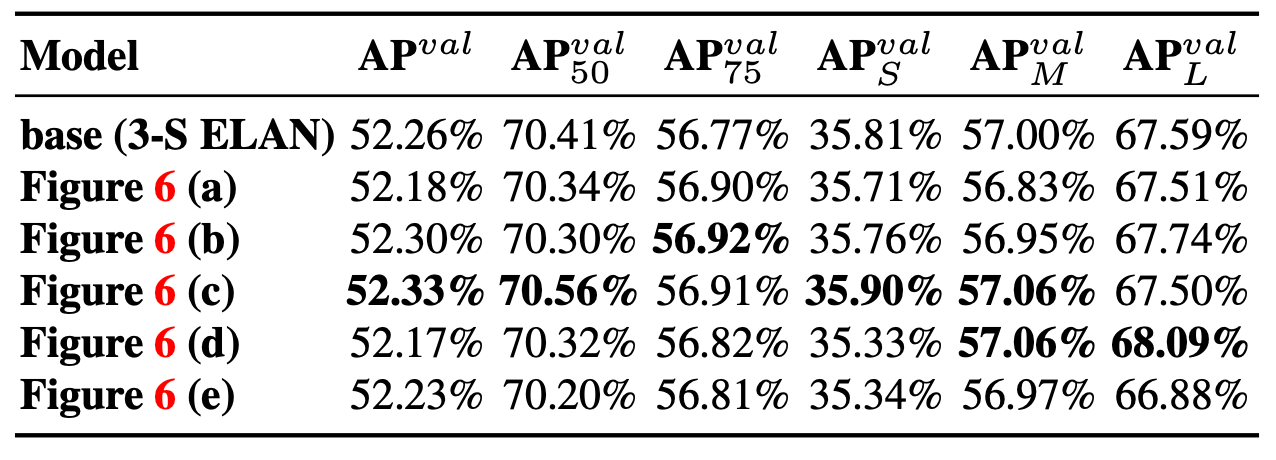
為了驗證模型重參數化的通用性,作者將其分別應用於具有 concatenation 特性的模型:3 個 block 的 ELAN 和具有 residual 特性的模型:CSPDarknet,發現所有更高的 AP 都出現在有參數化的模型中,如 表二、表三 所示。
Planned RepConcatenation model

Planned RepResidual model
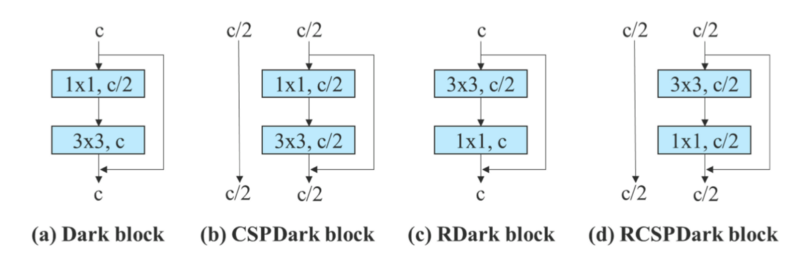
由於 dark block 在一開始沒有 3x3 卷積模塊,因此設計了一種反向 dark block (RDark block)。

2. Dynamic label assignment strategy (動態標籤分配策略)
深度監督是一種常用於訓練深度網路的技術,透過使用 auxiliary 的機制對淺層的網路權重進行訓練,其效果能對模型表現有顯著的提升,作者將最終輸出的 head 稱為 lead head,而用於輔助訓練的 head 稱為 auxiliary head,圖六(b) 展示了帶有 auxiliary head 的物件偵測器。
過去在深度網路的訓練中,通常會直接以 ground truth 來產生 hard label 來訓練網路權重,例如 CNN 分類任務,在近年來,除了 hard label,YOLO 還會利用模型預測的邊界框和 ground truth 的 IoU 來當做 objectness 的 soft label,作者把分配 soft label 的機制稱為 label assigner。
為了訓練 auxiliary head 和 lead head,目前最常用的方法就是各自獨立分配,也就是說使用它們自己的預測結果和 ground truth 來進行 label assigner,如 圖七(c) 所示,而作者提出了使用 lead head 預測的 soft label 作為指導,來產生 coarse to fine 的階層式 soft label,進而分別用於 auxiliary head 及 lead head 的學習,如 圖七(d)(e) 所示。

(d) Lead head guided assigner
以 lead head 產生的 soft label 同時做為 auxiliary head 及 lead head 的 target,這樣做的原因是因為 lead head 具有相對較強的學習能力,因此由此產生的 soft label 應該更能代表資料與 target 間的分佈和相關性。此外,還可以將這樣的學習方式視為一種 generalized residual learning,透過讓較淺層的 auxiliary head 直接學習 lead head 已經學習到的資訊,lead head 將能更專注在學習尚未學習到的 residual 資訊。
(e) Coarse-to-fine lead guided assigner
進一步地,作者產生兩組不同的 soft label,分別為 coarse label 及 fine label,其中 fine label 與 lead head 產生的 soft label 相同,而 coarse label 是透過放寬正樣本分配過程的限制來生成的,原因是因為 auxiliary head 的學習能力沒有 lead head 來得強,為了避免遺失需要學習的資訊,將重點優化 auxiliary head 的 recall 。
至於 lead head 的輸出,可以從高 recall 的結果中過濾出高 precision 結果作為最終輸出。然而,需要注意的是,如果 coarse label 和 fine label 的權重相近,則可能會在最終預測時產生不好的 prior,為瞭解決這個問題,作者在 decoder 中加入限制,使 coarse label 不能那麼完美的產生 soft label。上述機制允許在學習過程中動態調整 fine label 與 coarse label,並讓 fine label 的可優化上界始終高於 coarse label。
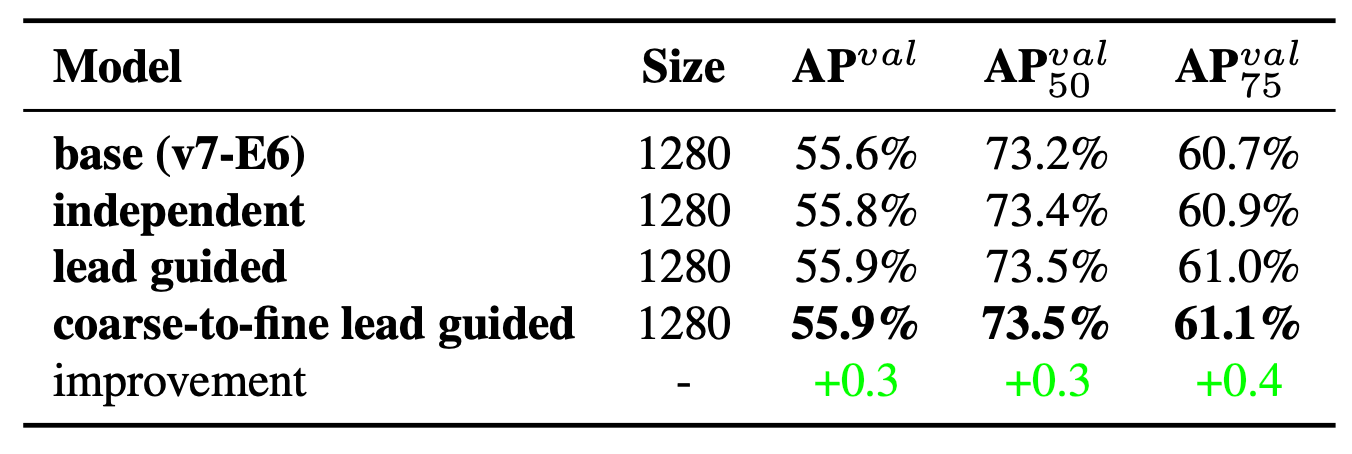
在 表二 中,可以看到使用 coarse-to-fine lead guided 技術可以在各個 AP 標準下提高準確率。
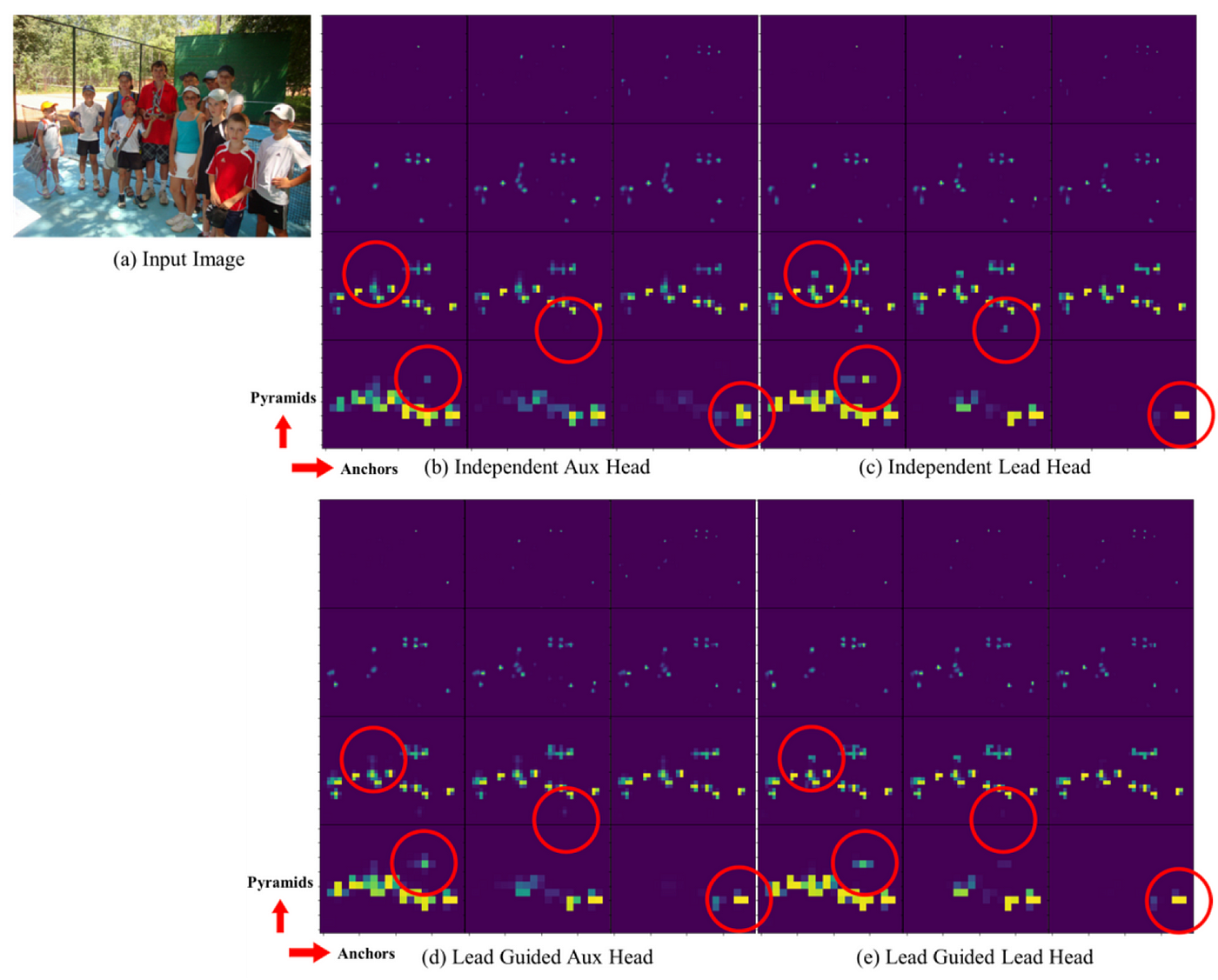
在 圖八 中展示了在 auxiliary head 和 lead head 上通過不同方法預測的 objectness map,發現如果使用 lead guided 方法,auxiliary head 的確會幫助 lead head 專注學習尚未學習到的 residual 資訊。
3. Other trainable bag-of-freebies
- Batch normalization
- Implicit knowledge in YOLOR
- EMA (Exponential Moving Average)
訓練官方程式碼如下:
Reference
[1] Scaled-YOLOv4: Scaling cross stage partial network (Chien-Yao et al., 2020) [Paper]
[2] An energy and GPU-computation efficient backbone network for real-time object detection (Youngwan et al., 2019) [Paper]
[3] Designing network design strategies (Anonymous., 2022)
[4] EfficientNet: Rethinking model scaling for convolutional neural networks. (Mingxing et al., 2019) [Paper]
[5] Fast and accurate model scaling (Dolla ́r et al., 2021) [Paper]
[6] RepVGG: Making VGGstyle convnets great again (Xiaohan et al., 2021) [Github]
- 主辦暨執行單位:
財團法人台灣人工智慧學校基金會 - 協辦單位:
中央研究院資訊科學研究所、中央研究院資訊科技創新研究中心 - 捐助企業:
台塑企業、奇美實業、英業達集團、義隆電子、聯發科技、友達光電、新光人壽-新壽管理維護
Copyright© 台灣人工智慧學校 | Taiwan AI Academy 版權所有