AI 紙本資料辨識之經驗分享 - Shu-Yu Huang
制式的紙本資料常常被用來傳遞、儲存資訊,像是履歷中會有個人的姓名、學歷等等資料,會被人資部門收集起來建檔。雖然在電腦上可以直接從資料文檔擷取資訊建檔,但有些場合還是有匯入紙本資料的需求,大致可以分為文本和標籤這兩種。文本資料擷取的情景(如圖1左)可能是印刷物需要紙本認證像是營業登記證等等文本,不能只看電腦上的資料,還要印下來籤核;或者是對印刷、手寫文本的資訊收集,像是將抄寫的水電瓦斯錶建檔。標籤資料擷取的情景可能是是文檔會被印下來貼在東西上面(如圖1右),會有從物品標籤擷取資料的需求,像是貨物的籤條會跟著貨物走,收貨方透過籤條才能認證對的貨品再建檔。要匯入實體紙本資料常常需要人工將紙本內容理解後輸入進系統,如果可以自動辨識拍下來的內容可以省去很多不必要的人力。
 圖1、文本和標籤範例
圖1、文本和標籤範例紙本資料圖片格式
對電腦而言,圖片就是一格格的像素,除此之外一般沒有既定的格式,例如拍合照,並沒有限制男生一定要站在女生左邊。而紙本資料圖片一般來講對文數字的編排會有既定格式,會將圖片分為各個區塊。因此紙本資料辨識大致分為兩種階段:文字區辨識、連續文字辨識。其中文字區辨識也可能分數個階段做,例如第一階段辨識文字區,第二階段辨識行,而最後再對分出的行中的文數字做辨識。以下會就兩個階段做說明。
A. 文字區辨識
不論是文本還是標籤的紙本資料圖片,大致上都可以分為無框線和有框線兩種情況。無框線的情況下會由相對位置來區分區塊,像是履歷上最上面是姓名、照片,下面是學歷、經歷等等,也可能左邊是經歷、右邊是證照,總之區塊間有明顯的區隔,如圖2所示。
 圖2、無框線紙本資料圖片範例
圖2、無框線紙本資料圖片範例另外還有一種是有框線的情況,直接以隔線區分不同意義的區塊,例如簽到表(圖3左)上會有欄跟列,欄表示不同項目、列表示不同序列;也可能是不規則的表格,例如貨物標籤(圖3右),每個格子會有不同意義。
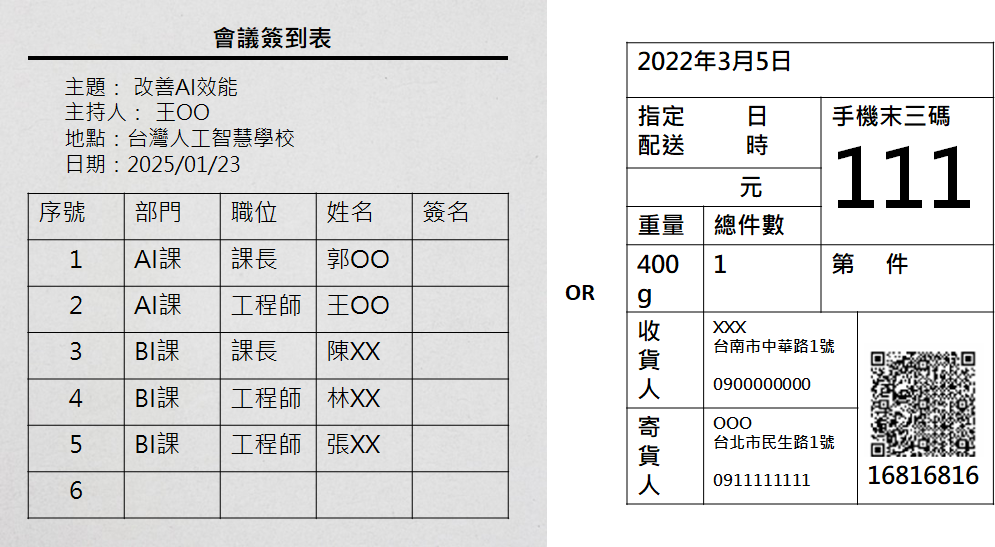 圖3、 有框線紙本資料圖片範例
圖3、 有框線紙本資料圖片範例若已經知道以上的格式則可以安排不同種類、不同布局的模型做相應的機器學習,這兩種格式區會有不同的文字區辨識方式可以用。通常會做一些資料增強來加強訓練效果,除了常見的旋轉、平移、亮度改變、色調改變之外過往也有試過將每個文字區剪下直接貼到別的地方做為增強資料,但卻得到反效果,不建議使用。應是剪下貼上的銳利邊干擾學習,且後來改成四周加上白邊後再位移則有較好的效果。
A.1. 無框線文字區辨識
例如為方便審核廠商資料建檔,會將對方附檔的證書key成文字,但這個建檔步驟繁雜又容易出錯,不過有固定想看的的項目,所以適合用AI做自動辨識。如圖4:第一階段會先判別文字區、第二階段辨識行、第三階段再來判別行中的連續文數字。
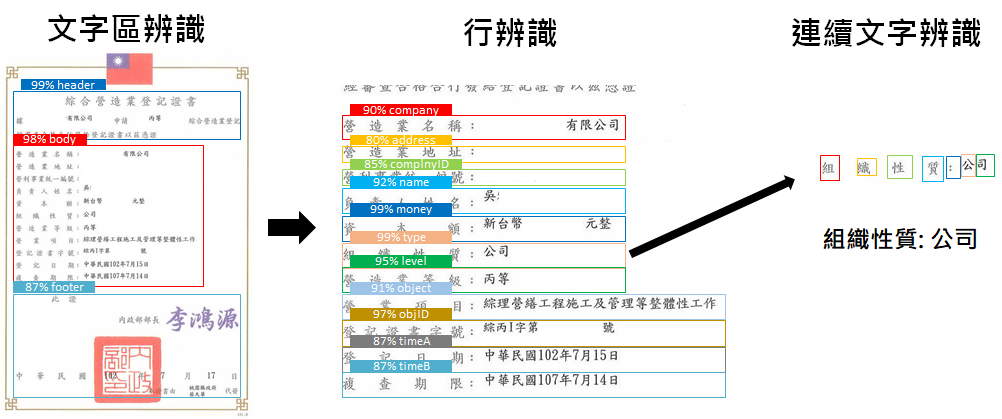 圖4、無框線紙本資料辨識流程範例
圖4、無框線紙本資料辨識流程範例若沒有框線,則文字區辨識一般都會定界為物件偵測問題,會用最小矩形框從圖片中框出各個類別物件(在這邊就是文字區)的位置、長寬、類別。以下介紹RCNN系列和YOLO系列的物件偵測。
A.1.1. RCNN系列
Regions with CNN features系列是標準2 stage network,會先生出很多預測框,在訓練時以最大化預測框及目標框的交集/聯集(IOU)為目標,若兩者有差距則IOU小(如圖5所示)接下來對這些目標框做類別預測。
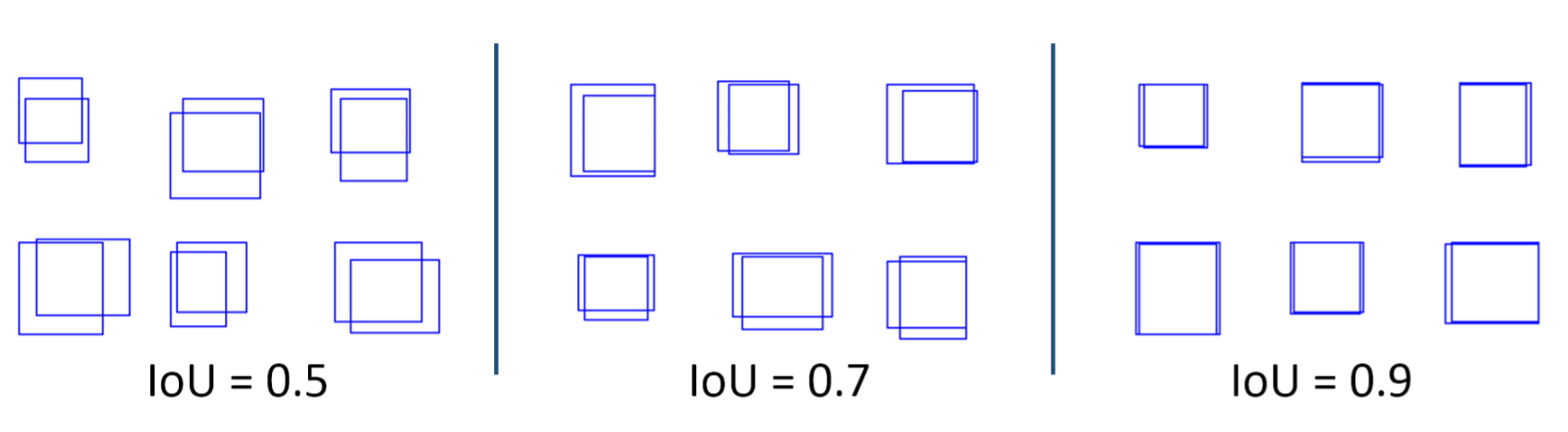 圖5、IOU示意圖
圖5、IOU示意圖初版會使用CNN生出無數個預測框,使用SVM對這些預測框進行fine tune,所以很慢。生出這個類型的loss後來還有許多改進,如Fast RCNN、Faster RCNN等等。後來的Faster RCNN使用Region Proposal Network以CNN抓出的feature map生出無數個預測框(proposals)拿來做感興趣區域(ROI)的pooling(不論是區域內平均還是最大值都算pooling)後的值做預測,大幅加快整體運作速度,如圖6所示。
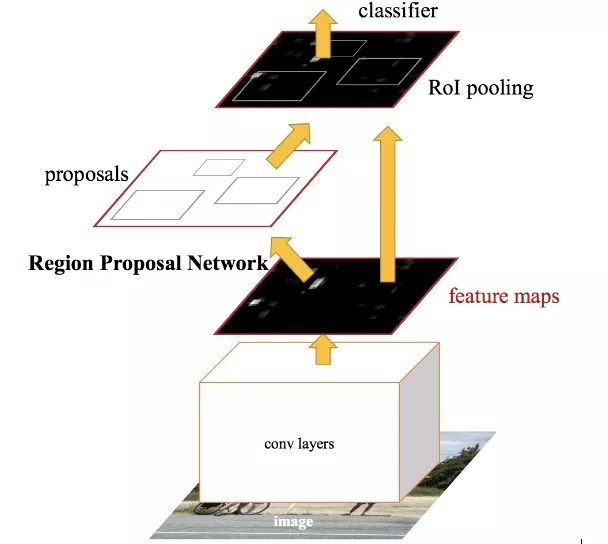 圖6、Faster RCNN中ROI pooling,來源為Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440–1448).
圖6、Faster RCNN中ROI pooling,來源為Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440–1448).A.1.2. YOLO系列
You Only Look Once系列希望使用CNN就能給出預測框的長寬、位置、類別。以 YOLOv1 為例,經過多層CNN還有pooling讓feature長寬成為7x7的大小,feature深度中每個維度有不同含義。它的想法是想將預測框的範圍侷限在7x7個格狀附近(如圖7左所示),然後去預測每個框離這個格子左上角的x,y距離(如圖7右所示),還有框的長寬、種類、可信程度。
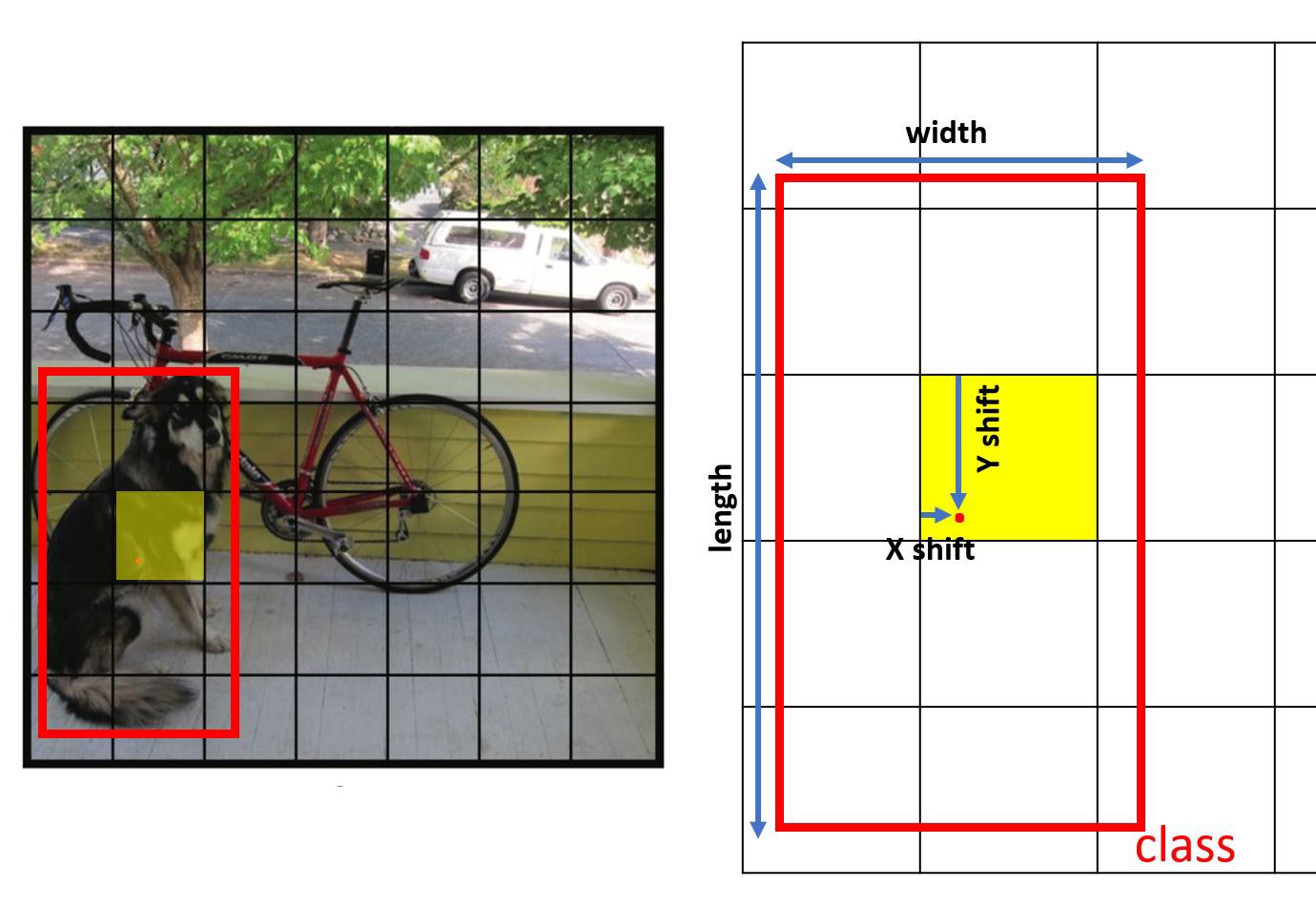 圖7、TOLOv1預測框改念圖
圖7、TOLOv1預測框改念圖後續又推出了YOLOv2、YOLOv3、YOLOv4等等在速度和準確度上有更多進展,如圖8所示,不過通常同一種YOLO速度快時準確度就會比較低。比較標準AP()是為框線IOU在某個基準(例如5%,50%,90%等等)之上時的預測準度,詳細可以參考外部連結。
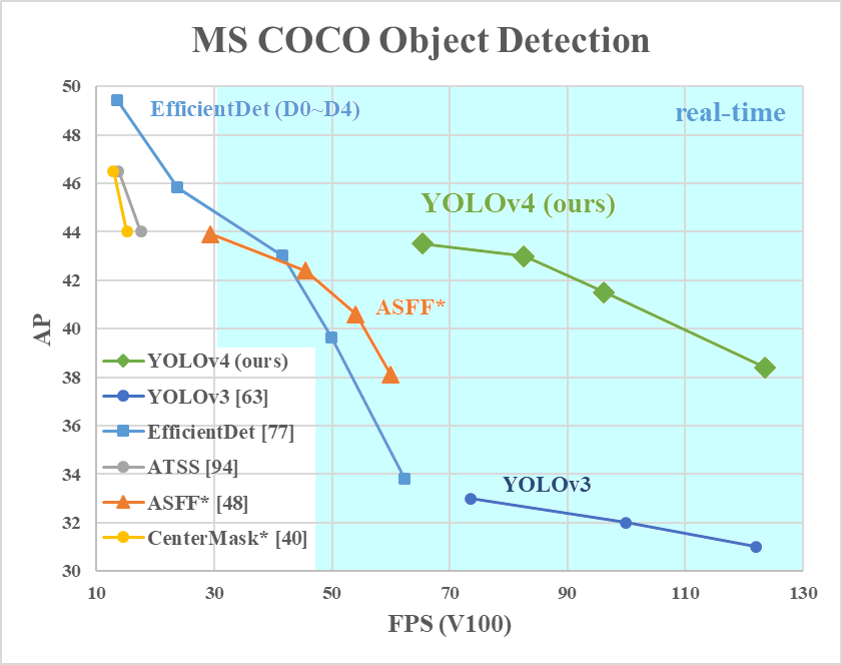 圖8、COCO Object detection AP大小比較,來源: https://github.com/alexeyab/darknet
圖8、COCO Object detection AP大小比較,來源: https://github.com/alexeyab/darknet目前最常用的YOLOv4在real time的執行速度下可以在 COCO dataset 達到44% mAP的準確度。而有時會將物件偵測重點放在速度上,那就有Fast YOLO系列可以用,如圖9所示。後來有Fastest YOLO將back bone CNN model改成Efficient net後讓速度還能再更上一層。
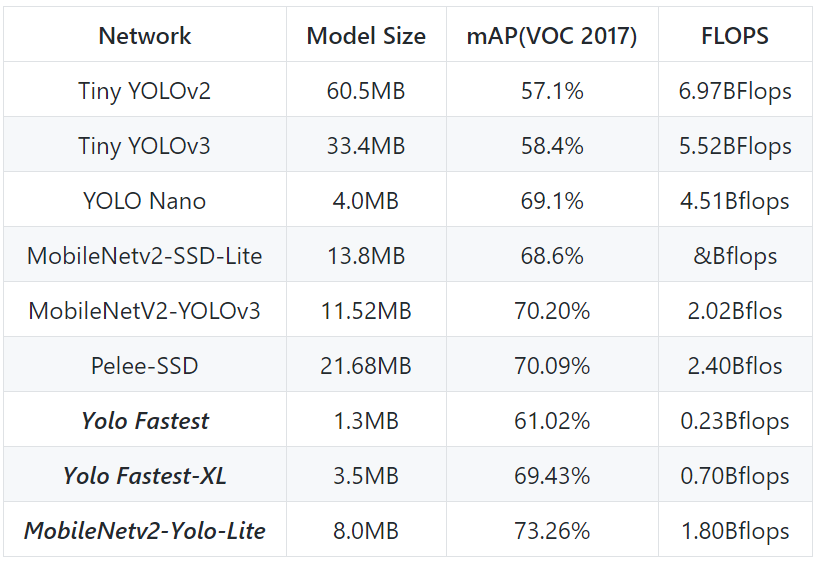 圖9,比較各代yolo準度及速度,來源: https://github.com/dog-qiuqiu/Yolo-Fastest
圖9,比較各代yolo準度及速度,來源: https://github.com/dog-qiuqiu/Yolo-FastestA.2. 依框線辨識文字區
例如倉儲人員需要將貨物標籤資訊建檔、或比對資訊,提供給客戶及貨運公司,那很多貨物的標籤上就有用框線分割文字區,可以透過辨識框線來區分文字區。如圖10:第一階段會先判別標籤、區塊或特定代碼,第二階段再來判別區塊中的連續文字、數字。
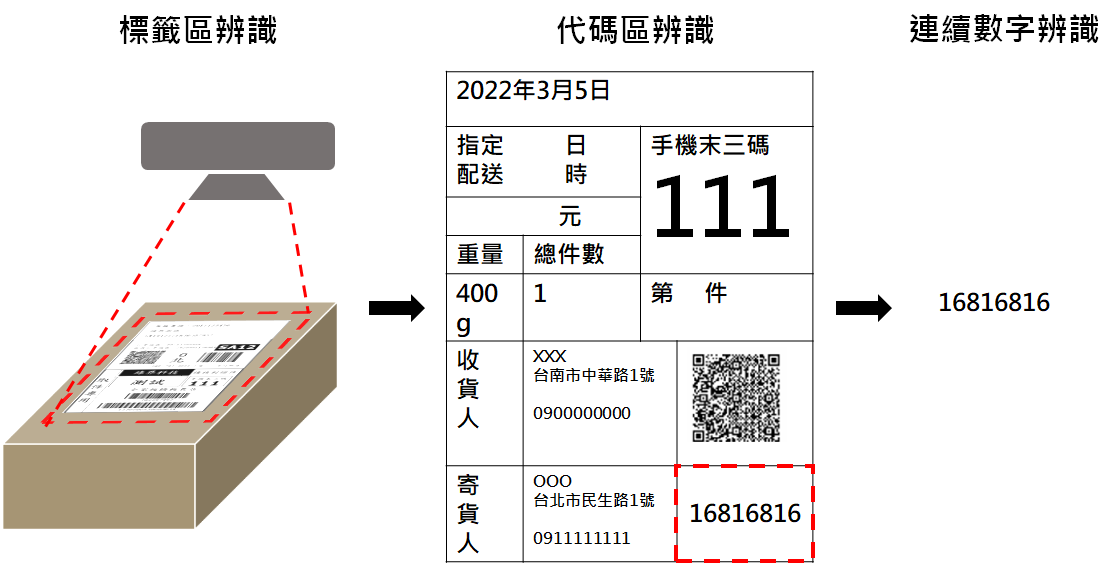 圖10、有框線紙本資料辨識流程範例
圖10、有框線紙本資料辨識流程範例若紙本中有框線,除了可以定界為物件偵測問題外亦可以定界為影像分割問題。
A.2.1. 物件偵測
與前面無框線圖片的文字區辨識一樣,可以使用RCNN系列或者YOLO系列來偵測,都可以得到不錯的結果,如圖11所示。
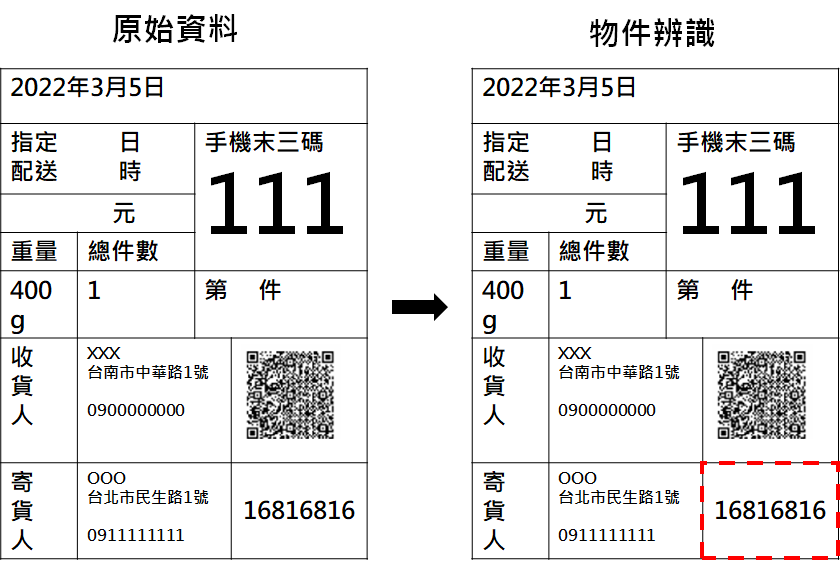 圖11、使用物件偵測方法辨識有框線圖片的文字區
圖11、使用物件偵測方法辨識有框線圖片的文字區A.2.2. Table-OCR影像分割
基於框線的特性,透過影像分割演算法將原本的標籤中有框線的部分一條一條偵測出來,接著透過預先的定義查找該項目的位置。例如我要找下列標籤中右下代碼的部分,就是介於X_line6到X_line7之間,還有Y_line3到Y_line4之間,見圖12。Table-OCR使用Unet網路去切出圖片中的直線和橫線,再混合使用opencv的erode,dilate將直線橫線精化,參考chineseocr/table-ocr。
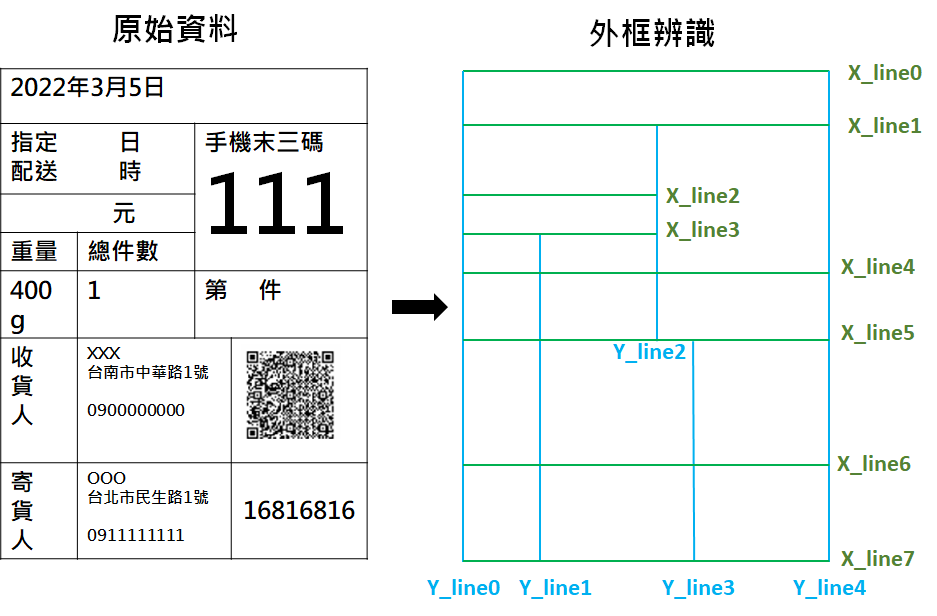 圖12、影像分割找出框線示意圖
圖12、影像分割找出框線示意圖為確保line的位置有對到還要做圖片歪斜的校正,簡單的方法是根據偵測出來的最左邊和最上面的線的邊緣找到三個角落來校正,範例是使用X_line0,Y_line0找出三個點,接著對左上到右上連線的傾斜角度做校正,如圖13所示。
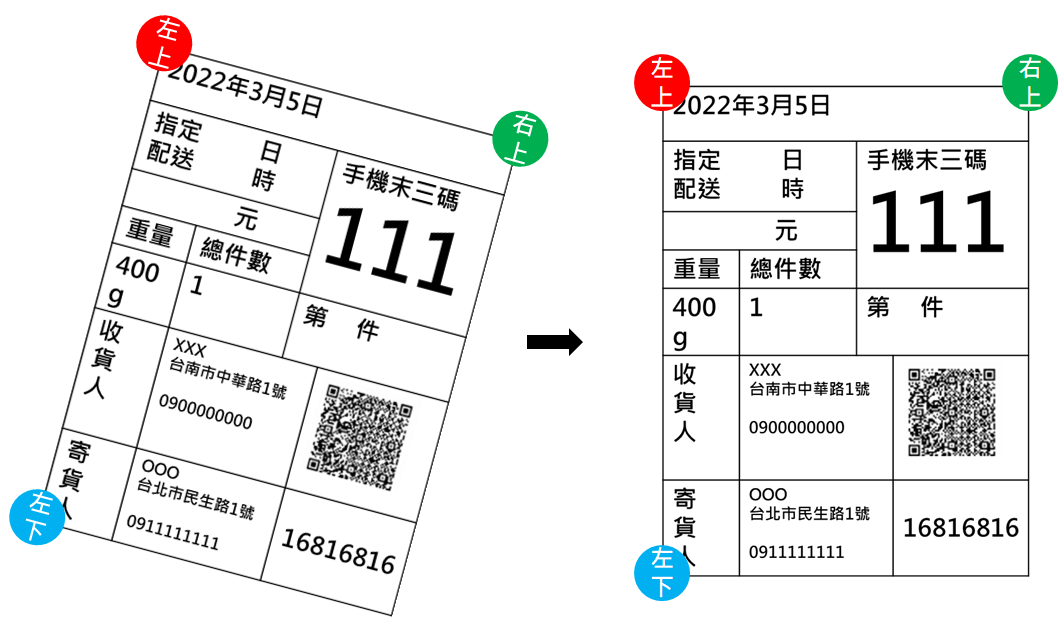 圖13、校正圖片歪斜
圖13、校正圖片歪斜B. 文數字辨識
當利用文字區辨識模型找出文字區塊後,就可以開始接著做文數字辨識。文數字辨識的作法比較多樣,可以用sequence to sequence的方式來解,亦或者當成物件偵測問題,甚至如果可能結果的範圍不大(例如判別數字串),則可以當成影像分類問題。為訓練文數字,首先會將前步驟文字區判別出的最終結果存起來,然後做影像標註,值得一提的是,使用遞迴式的標註可以增快標註速度:第一次標註200張,訓練過文數字判別後使用訓練好的模型自動標註200張,修正200張的偏差後,使用400張辨識…,依此類推直到標註完全部照片,可以節省90%的時間。也可以嘗試加入使用常見的數據集例如MNIST手寫數字資料集合成圖片增加訓練資料量,像是在空間中任意塞放大縮小過的MNIST數字,以期提供更多樣的數字組合來強化訓練效果,如圖14所示。
 圖14、MNIST組合的影像
圖14、MNIST組合的影像若文數字其實不是MNIST那種手寫文字而是印刷文字,則需自製印刷字體資料集,可以使用簡單的Excel把所有可能文字打出來存成圖檔。在資料上需做多種的資料增強,包含加上雜訊、銳利化、調整亮度、色調等等,都是為了適應不同的紙質以及拍攝情況,如圖15所示。
 圖15、對文字做各種影像增強
圖15、對文字做各種影像增強那以下就介紹幾種文數字判別的方案。
B.1. Sequence to Sequence Model
文字辨識可以透過sequence to sequence的模型來做,會從某橫向掃過圖片,對圖片單向或雙向的做解析,有點像人類辨識文字的方式。這邊介紹方便的套件Tesseract 4.0,它是一套LSTM-based的開源光學文字辨識引擎支援30種以上的語言,能分析整頁文件資料、 支援垂直書寫辨識。主要結構是將input圖片以sliding window方式由左至右(forward)還有由右至左(backword)輸入進兩個不同的LSTM中,如圖16上半所示。再來將輸出concatenate起來(也就是bi-directional LSTM),再丟入1x1 convolution壓縮channel最後使用sigmoid做output activation,如圖16中間模型圖。最後輸出會是window中偵測到某個文字與否,所以常常偵測到空字元,可以藉由空字元數量判斷是否真的是空字元(e.g. 大於2個),如圖16下半部。
 圖16、Tesseract運作模型
圖16、Tesseract運作模型輸入資料為未經壓縮的標籤圖像文件格式(TIFF)並且背景為淡色或白色,所以需要前處理轉成灰階,如圖17所示。簡體中文能直接在上面訓練,若為繁體中文則需繁簡轉換。
 圖17、將圖片灰階處裡
圖17、將圖片灰階處裡目前大部分印刷字體都使用Tesseract來做辨識。
B.2. 物件偵測
文字判別問題也可以化為數個單文字或數字的物件偵測問題,如圖18所示。可使用YOLO或RCNN系列做判別,他們的各個版本這邊就不再贅述。
 圖18、單文字、數字物件偵測
圖18、單文字、數字物件偵測這邊以手寫數字辨識為例,可以使用使用labelimg標籤,如圖19所示。
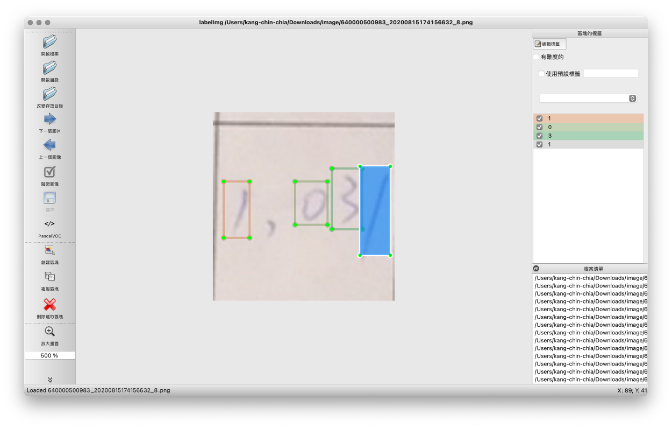 圖19、使用lableimg做標籤文字的物件框
圖19、使用lableimg做標籤文字的物件框使用結果大致如下,在一個範圍中框出所有的數字,並算出對該數字的信心指數。例如圖20所示每個數字都很有信心,數字排列應是1103。
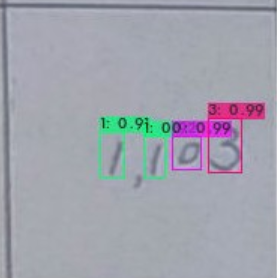 圖20、使用物件偵測辨識文數字結果
圖20、使用物件偵測辨識文數字結果B.3. 影像分類
出現的文數字排列組合較少時可以考慮直接做影像分類。若可能的種類有多少種就分多少類,適用於固定文數字數量的情況,例如上例手機末三碼為3個字,則可能的分類就是000~999共1000種可能。而模型的話則可以參考paper with code image-classification排行榜,如圖21所示。
裡面會持續更新時下最有能力的模型,且每個資料集有分開排名,建議從樣貌和目標接近的資料集的排行榜來選要使用的模型。 其中過往專題最熱門的是Efficient Net系列,其中Efficient Net B4通常能達到速度和準確度的最佳平衡,如圖22所示。
 圖21、image classification排行榜
圖21、image classification排行榜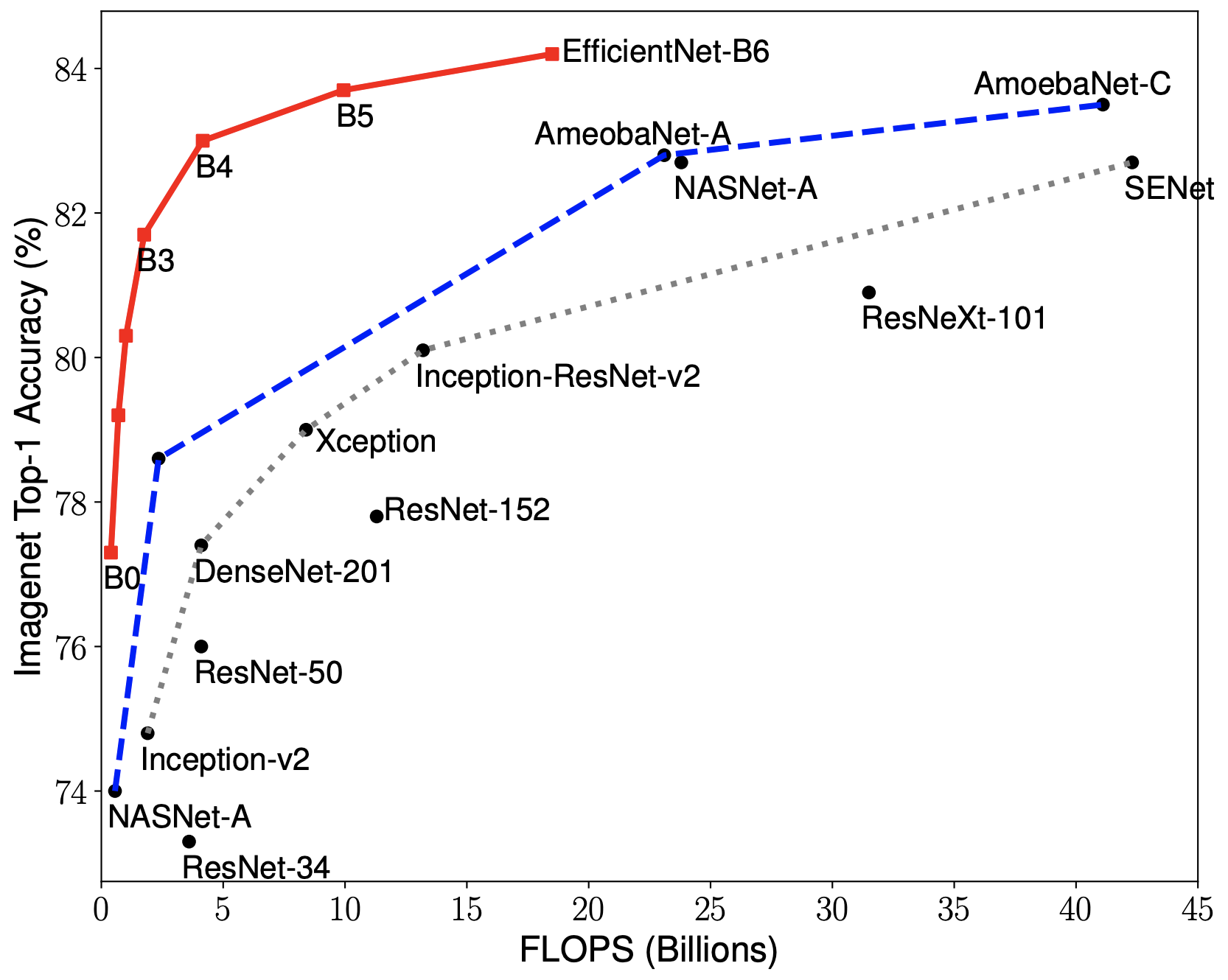 圖22、各種classification網路做Image net的top-1 accuracy。Y軸為accuracy、X軸為速度。Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105–6114). PMLR.
圖22、各種classification網路做Image net的top-1 accuracy。Y軸為accuracy、X軸為速度。Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105–6114). PMLR.小結
以機器學習實作紙本資料辨識大致上是為了實體的標籤、文本建檔和認證。其中模型大致上會先做多階段的文字區辨識再做文數字辨識。視資料中有無框線,文字區辨識可能可以用物件偵測或者影像分割的方式做各階段的文字區辨識。依照紙本常常是均質的特性,比較特別的是常常可以使用剪下區塊貼上的方式做資料擴增。另外,紙本辨識依case會有不同的階段,但一定包含文數字辨識,方法多元,可能可以用sequence to sequence、物件偵測或者影像分類方式去做。紙本的文數字辨識要考慮使用的是手寫還是印刷文字,若是手寫英數字可以使用MNIST合成資料擴充訓練資料;若是印刷文字則可以把文字存成圖檔再合成資料擴充訓練資料。最後在模型選擇上,不論是物件偵測、影像分割還是影像分類,都可以從paper with code上面尋找該議題中最新最好的模型來用。
希望本文對想做機器學習,紙本辨識的同好有幫助!
References
- (RCNN)Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580–587).
- (Fast RCNN)Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440–1448).
- (Faster RCNN)Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv preprint arXiv:1506.01497.
- (YOLOv1)Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779–788).
- (YOLOv2)Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263–7271).
- (Fast YOLO)Shafiee, M. J., Chywl, B., Li, F., & Wong, A. (2017). Fast YOLO: A fast you only look once system for real-time embedded object detection in video. arXiv preprint arXiv:1709.05943.
- (YOLOv3)Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767.
- (YOLOv4)Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
- (Tesseract)Smith, R. (2007, September). An overview of the Tesseract OCR engine. In Ninth international conference on document analysis and recognition (ICDAR 2007) (Vol. 2, pp. 629–633). IEEE.
- (U-net)Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234–241). Springer, Cham.
- (Efficientnet)Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105–6114). PMLR.
- 主辦暨執行單位:
財團法人台灣人工智慧學校基金會 - 協辦單位:
中央研究院資訊科學研究所、中央研究院資訊科技創新研究中心 - 捐助企業:
台塑企業、奇美實業、英業達集團、義隆電子、聯發科技、友達光電、新光人壽-新壽管理維護
Copyright© 台灣人工智慧學校 | Taiwan AI Academy 版權所有